I am building a new XCP-ng/Xen Orchestra (replacing a vSphere model). Everything works, but I can’t get migration to work at 10G speeds. I moved the management connection to 10G, and the Synology NAS/NFS connection is also on 10 G. All the connections on the two Hosts and two Storage devices are on 10G. The management is on a VLAN, and the storage is on a Cisco switch that is not associated with the rest of the network. When I ran this same transfer in VMware, I could transfer from one storage to another with the VM turned off in 4-6 minutes. In Xen, it takes 30+ minutes. I watched the throughput on the XOA and the host, which was between 50 to 60 MB. If the VM is off, it gets up to 70-80 MB, but it still takes 30 minutes. If I do a iperf from XOA, I get sold 800 to 900 MB, so I know the connection is sound. I am open to all suggestions; this is still preproduction, so I can change most settings without affecting the company.
Are you running the latest 8.3RC2 with the latest XO build? In XO do you have the latest guest tools installed?
How big are these VMs? I’ve never had one take more than a few minutes, and still not using the full 10gbps.
Thank you for the replies. The XOA version is 5.95.2, the latest stable update. I am unsure where to find the guest tools version, but I see Management agent 1.0.0-protp0.4.0 detected. The test VM is an 80G flat.vmdk. I may have found the problem, but I hope to fix it today. The Synology box has a 10G 172. x access for the NFS drives being used for VDI. However, I realized the VLANx for the management portal of the Synology box was a 1G NIC. So, I think the traffic is going through XOA on VLANx and not over the 172.x. I will update the 10G switch and connect Synology management to 10G, which should solve the problem. Posted again after the changes.
Coming back to reply, I’m now finding that it is taking longer to move VMs from one storage to another, now reporting around an hour each, but in reality it is taking about 30 minutes. I have a few snapshots on each and I think this is adding to the amount of data being moved.
Found a drive that has an error on the main storage, going to migrate off of that server and fix the drive, plus update to latest Truenas Core while everything is away from this storage.
Sadly, moving the Synology management from 1G to 10G did not solve the problem. Nothing has changed. All connections are between two Cisco switches, and all are 10G. The Xen environment is entirely connected with a 10G NIC and still takes 30 minutes to move a powered-off VM. Do you have any ideas or things I might want to test or check?
OK, I dug into this a little, and it seems to be a limitation that they are working on:
I’m using NFS for storage.
Would changing the MTU to 9000 help?
I decided to try migrating 2 VMs at once, the average speed increased to right around gigabit, so I’m guessing I could get around 4 migrating at once and still have a little bandwidth across the disks.
I also tried migrating both of these from my LAB XO which goes through a router, didn’t make any difference in speed, which is what I thought. I mostly did this because I needed to migrate the product XO and didn’t want to do this while it was in use, even though I’ve tested this before.
Thank you for the (VDI SR migration capped at 1gbps) link. I’m not sure if this is still where the problem is. I have done some more testing. I built a new Windows 10 VM, and the storage-to-storage transfer was better. The VM powered off for 5-8 minutes, and the powered-on transfer was 10-15 minutes. This is a liveable transfer speed for storage. We migrate between hosts much more than with the storage device. I also discovered that the Windows 11 VM I used for the test earlier was imported from VMware. I’m not sure if imported VMs are more challenging to transfer.
Because beating the dead horse is fun…
Here’s a picture of migrating 2 VMs from shares to local (the reverse holds true as well but even better).
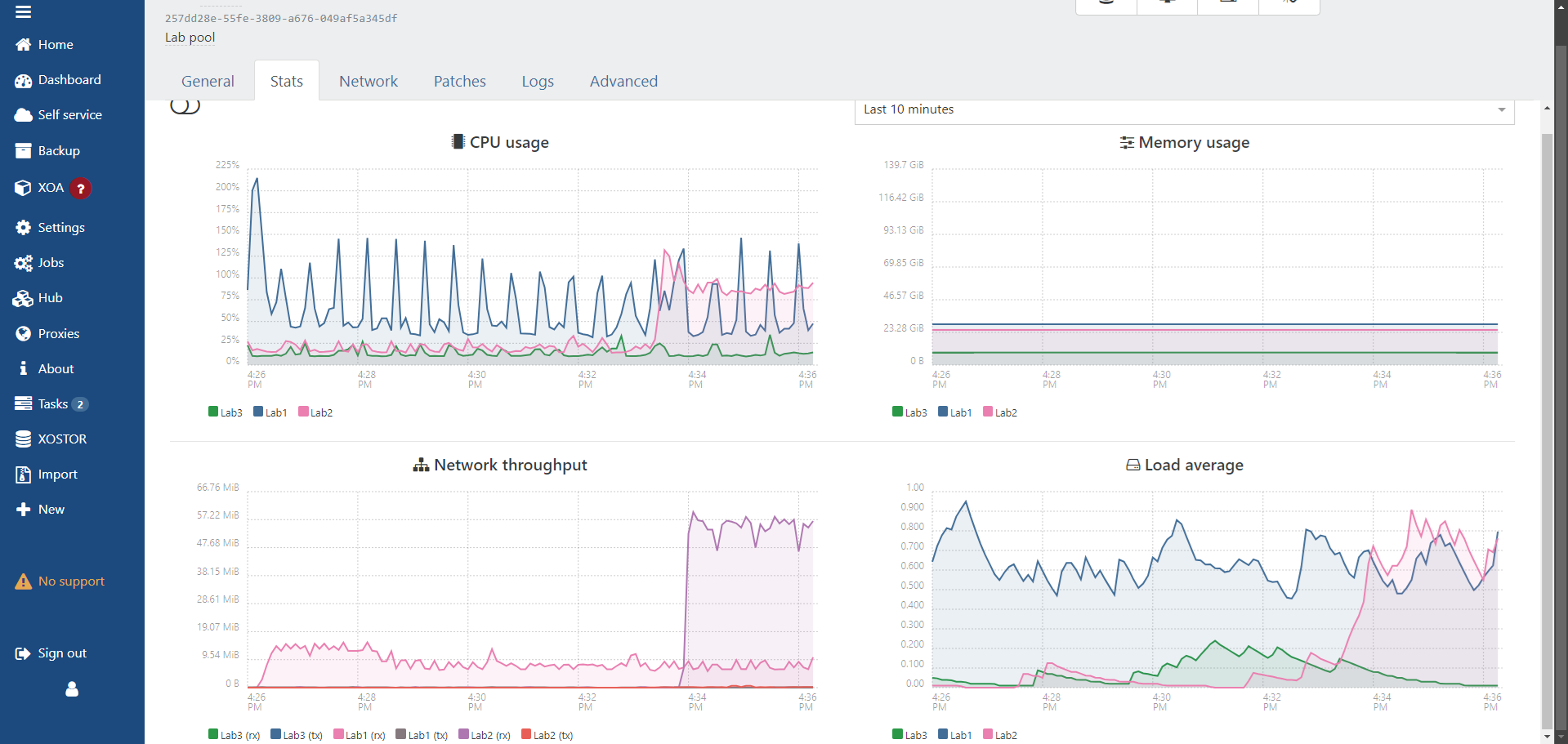
Lab1 is migrating from NFS to local, Lab2 is migrating from SMB to local. There is a 5x increase with SMB. Yes I’m running XCP-NG 8.3 latest (just updated today). I also burned the Truenas down and rebuilt from scratch with 24.10 Beta (Electric Eel). When I finished getting the storage set up, I migrated all 3 VMs (it a lab and not much going on right now) from the local of 3 hosts to the SMB share, it was getting over 2 gbps, once one of the VMs finished, it was closer to gigabit and remained at about 700mbps while the last one finished.
I think I’m going to test more of the SMB share for a while, just for the speed increase. Also I know that the disk speed isn’t an issue here, there is enough RAM on my Truenas to cache the entire VM (only 13 GB worth of a Windows Server VM), currently sitting at 70GB cache which is still bigger than the VM that is struggling to migrate.
I see that SMB share is available in XCP-NG 8.2 (current), I may try moving some of my less essential production VMs to an SMBshare and see how it goes.
I really think your bottleneck are the drives themselves. Can you even get 1GB(not bit) transfer with SMB or NFS?
No question the drives are hurting this, especially in the system above because everything is older and slower.
But performance isn’t a lot better in the newer and faster machine, NFS transfers still only move at around 65-80MBps and SMB are double that amount. I’m doing some tests right now and transferring from NFS to SMB is 65MBps out and 120MBps in and around 25 minutes to do this on a live Windows VM that is around 30GB in actual size.
This test is being done on the newer faster storage and I’m also running a disk speed test against the C: drive to see what might be happening here. It’s possible there will be no difference in the C drive test and this is just a migration thing.
As far as the disks go, the faster storage are 8 HGST 1TB disks in a RAIDZ2, so maximum I should be seeing is going to be 600MBps (give or take). I’d be extremely happy to see migrations at 300MBps or faster, but I think the most I’ll get is 150MBps or so per VM.
I’m starting to think that there is a blocking routine in the XCP-NG software to limit the bandwidth any single process might use, this would be to allow multiple things to have some bandwidth.
OK, for my system, I’m pretty convinced. These tests are done on my production system which has a more modern storage array. Supermicro X10, 6c12t Xeon E5-2603v4 with only 32GB of RAM, Truenas Core 13-u6. XCP-NG 8.2 latest (updates were applied before testing) with Xeon Silver v2 10c20t and 128GB of RAM. 10gbps networking on both with a Mikrotik CRS309 switch between them and DAC cables, Router OS 6.xx (yes it needs an upgrade).
First test was NFS because it was already there:

Second test was after migration to the new SMB share:
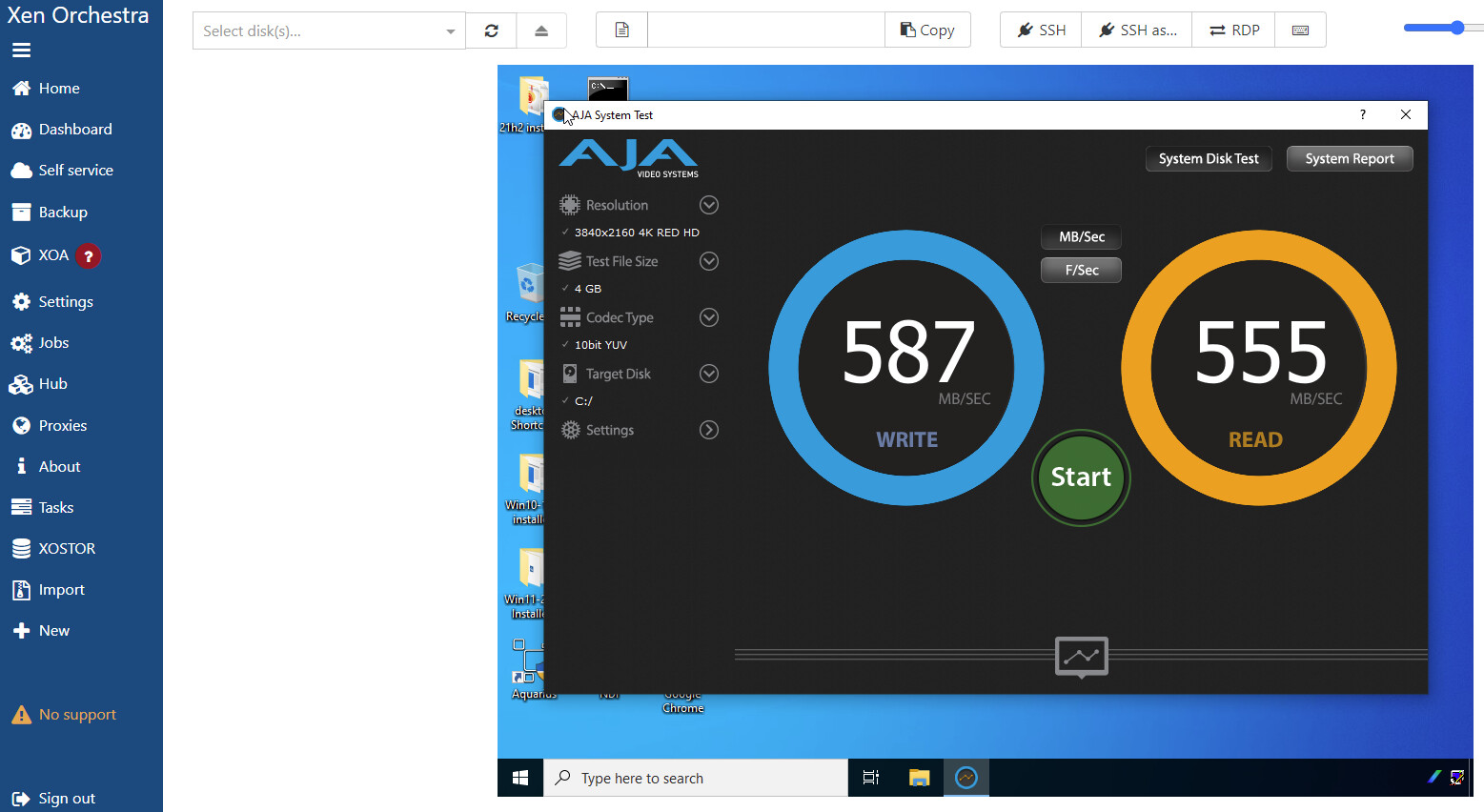
This second test was so fast that it didn’t even register on the Stats graph for this VM, the sample time was longer than the complete test.
Now did this just use the RAM cache in Truenas? It’s a small test so maybe, but clearly the NFS test did not. I’ll do a much larger test to make sure this isn’t all cache with the SMB test, but seeing as how this is close to what I think should be a maximum speed from this array, I don’t think the RAM in the Truenas had much to do with it.
[edit] Here is a test with a 16GB “file”, the results are pretty much the same. The ZFS cache was reported as 8GB and never increased during this test.
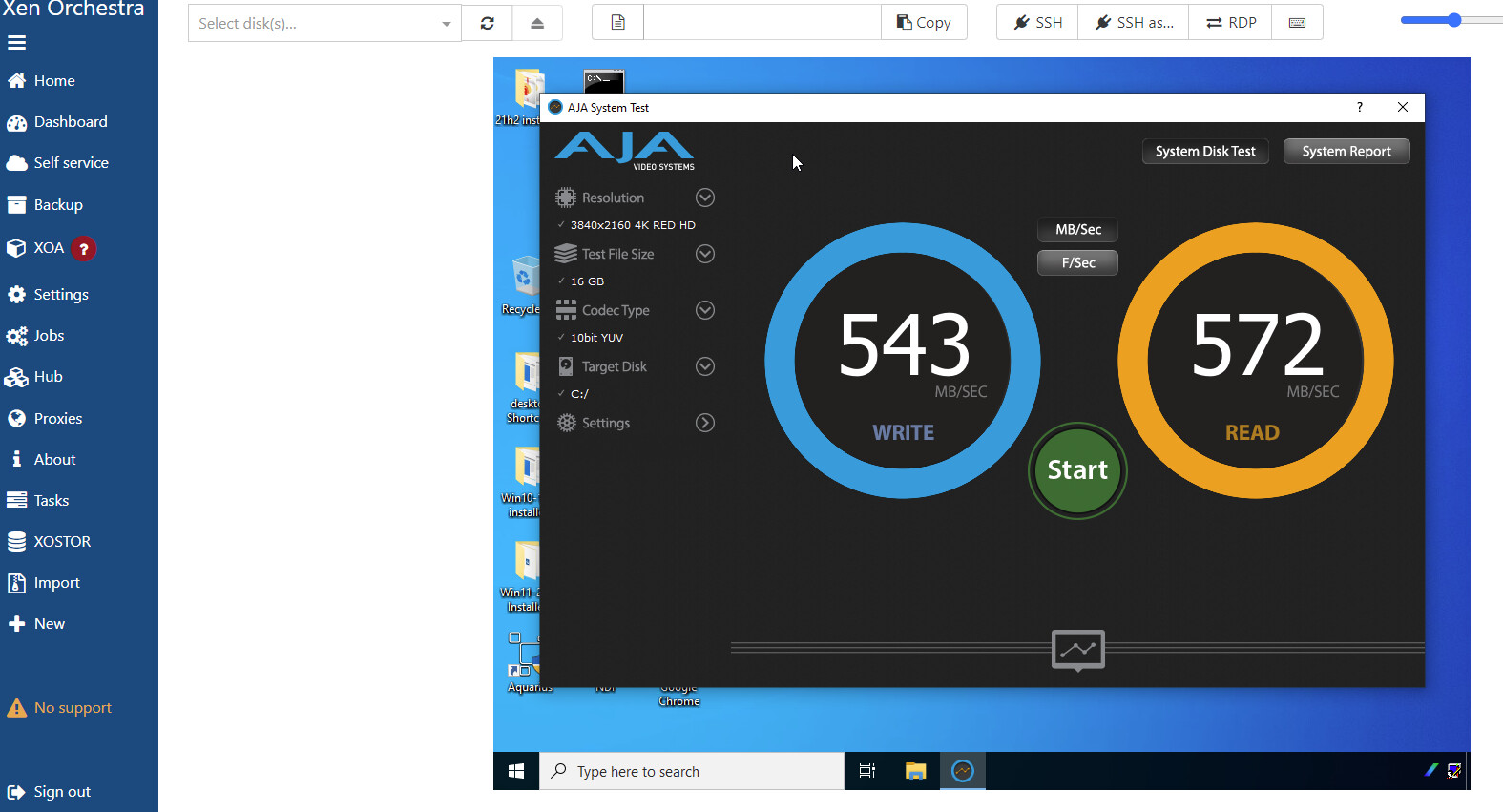
[edit 2} the RAM definitely has an impact, running a 64GB file and the first quarter showed 800+MBps, just like I would expect from a RAM cache, it slows down to roughly 400MBps by the end (average speed?) Reads are still 550+MBps and don’t seem bothered by the cache, they start and end about the same speed.