Recently my Truenas NFS share has slowed to less than gigabit speed, connected 10gbps to all my hosts. I found this during the latest Microsoft updates and had a difficult time getting all 5 servers updated. I’m currently migrating to a backup NFS that I already had attached which appears significantly faster, again connected 10gbps to the hosts.
Main storage is Supermicro X10, onboard SATA, eight drives at SATA 3gbps
Backup storage is Supermicro X10, onboard SATA, 4 drives at SATA 6gbps
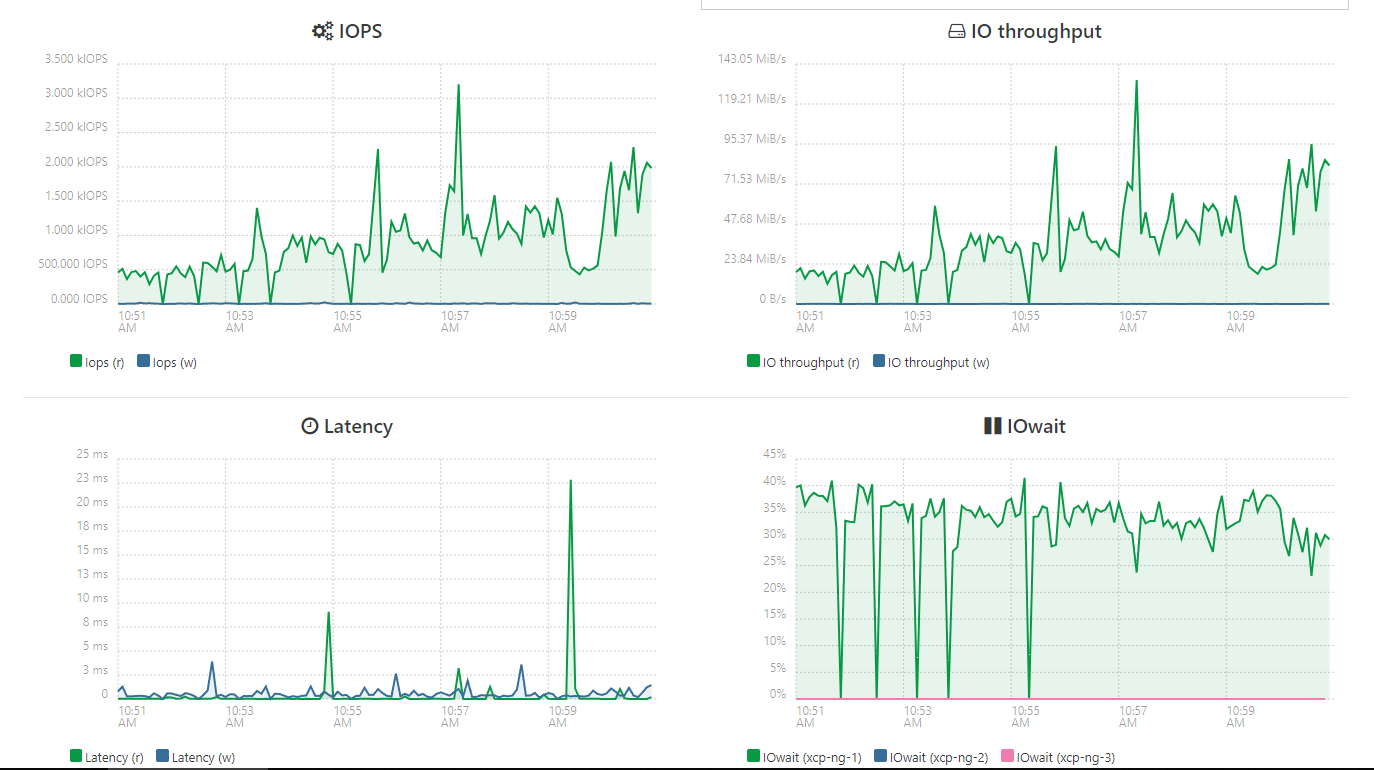
Now the main storage used to be faster, by a lot. Looking at the charts in XO-CE, I see 40% wait times shown, back up storage shows less than 1% wait times. Here’s a picture:
Getting ready to destroy and replace all the disks in the main storage, need to go to smaller disks so an actually destroy and replace is likely going to be needed.
In that picture, XCP-NG1 is master and Master seems to handle all migration duties, even if the VM is attached to another host.
Truenas Reporting shows the main unit disks as 60-80% busy, and maybe 25% busy on the backup.
Am I correct in thinking something is wrong with either Truenas or the disks on the main unit? As long as the main storage will be empty, I’m going to update to latest Truenas, it’s currently back on v12.x