Hello all,
as the title suggests I have VMs that will seemingly randomly crash on my server and then I have to go back into Xen Orchestra and turn them back on. Sometimes they boot right back up sometimes they crash on boot a few times before booting up.
I have run a hardware test using Dell’s built-in one in Lifecycle Controller and it says everything is fine. I have looked through all of the log files listed on XCP-ng’s Logfiles Page as well going through their Troubleshooting Page and haven’t seen anything that jumps out to me. I know that there are some log files on the VM’s themselves but I haven’t had a ton of success with these but will rummage through them again today
All that being said, I am kinda stuck as what to do now for troubleshooting steps and was hoping someone on here could point me in the right direction. Below are the specs of the server, thank you for any help and time in advanced!
Dell Poweredge R730XD 2x Intel E5-2680v3 2.50Ghz 128GB RAM 12 2TB SAS Drives in RAID6 done through Dells Lifecycle Controller
I am thinking the same thing, weirdly though I never had a VM issue on this server with ESXi. In digging through a log dump I found these errors showing up. I will update to 8.1 and post what logs I get to XCPs forums if I see anything noteworthy
I actually had this happen to me on my xcp-ng installation 8.0 about 6 months ago. I had built the hardware myself. Logs never revealed anything. The VM’s would randomly lockup or go down – I was seeing this about every 24-72 hours. Maddening since nothing ever showed in the logs. I smartested my drives and then mem86 tested my RAM. Without boring you with the details, it turned out to be bad RAM modules. 2 RMAs later (yes the first replacement RAM was found bad too by testing), the unit has run great ever since. That’s probably where I would start.
Man, you are in a world of hurt. Do iDrac logs provide any clues?
On our HP DL380 g6 Citrix XEN 6.5 hosts, experienced horrible issues after applying the MeltDown and Spectre patches. Both Linux and Windows VMs would no longer boot at all or fail in at least one out five boots. They would also crash after running.
The main problems were getting it to boot at all even if just one out of five times. Linux required booting with rescue ISO and removing a bad grub kernel filesystem and then reverting to an old kernel. Became familiar again with dracut. Booting and then updating to a new kernel.
Windows VMs required uninstalling patches, freeing hard drive space, lots more time, and a few machines lost for ever.
But that has not been an issue so much with later firmware and Xen patches and not on xcp-ng at all.
Were these Virtual Machines migrated from vmWare or freshly created on xcp-ng? Anything else in common with these VMs that crash? Is it physical CPU #31 always the one that crashes? There is some command (probably in grub) to disable particular CPUs.
Is there plenty of hard drive space inside these virtual machines?
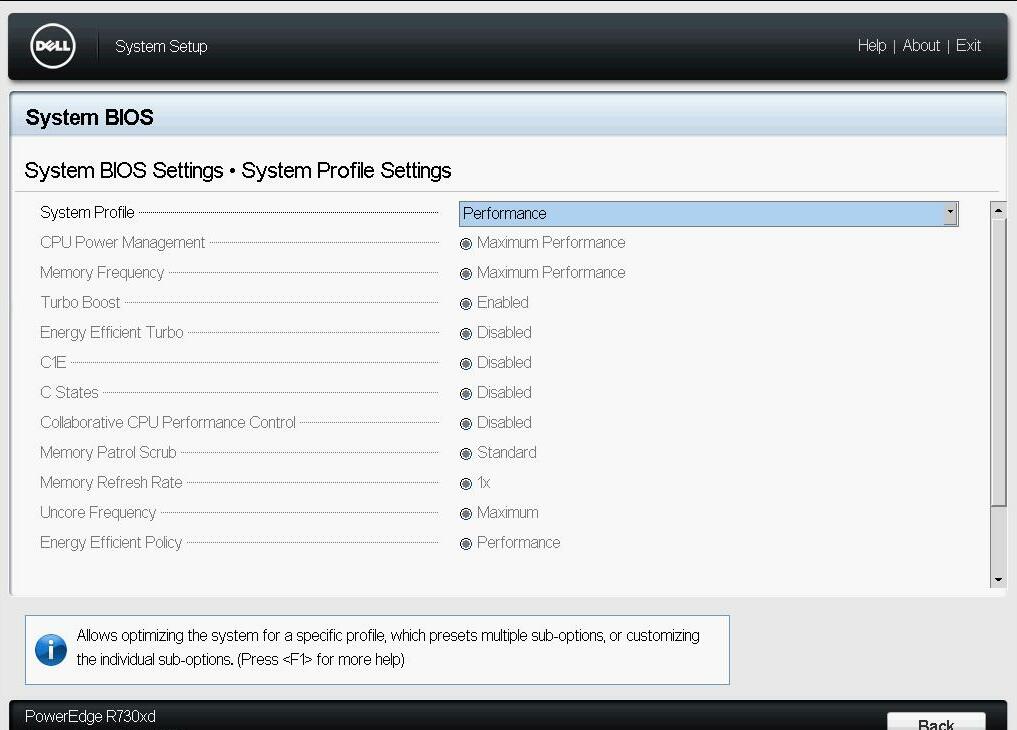
Just a thought, as I had similar issues out of the blue, a month or so back - check your BIOS settings and be sure there are no CPU power saving features (i.e. C3) turned on or anything for ultra low power states. It seems when the CPU goes into a low power state the VMs can crash. Once I turned off those settings, everything has been fine. I, too, ordered new RAM before I tried the BIOS settings and discovered the RAM was fine all along.
I rechecked the firmware and drivers to make sure everything was up-to-date, it was. I decided to try even more testing so I removed the array and excluded a drive from it and installed xcp-ng on that drive alone so the array was entirely out of the question, still the same issues. I now have Windows server 2019 installed on it and am running Prime95, figured I will let that run for the night and see what I get in the morning.
To answer some of your questions,
the bios was setup to Performance per watt, however, I did change this to straight performance and gave that a shot before installing windows onto it (got the same issue; Windows has been running fine for an hour so far). I will double-check the bios settings again tho to make sure I didn’t miss anything on the CPU section specifically
I am giving each VM plenty of hard drive space to ensure that isn’t the problem, 100-200gb for Ubuntu with very little in the way of software on them
I haven’t found anything useful at all in iDRAC and XCP-ng itself never crashes
All VMs are fresh installs of the OS’s in XCP-ng environment
All the ram is ECC
As far as CPUs crashing specifically I’m not sure. I have noticed on creating VMs if I set the CPU count to something like 20 (I’ve messed with less and more as well), the VM will boot but always crash before fully getting to install screen or crashes during install…this is why I decided to just test the CPUs. this is actually what my original post on XCP was describing. To get them to install fine I would have to set the CPU to something like 1-4. RAM setting doesn’t seem to be a decideding factor, ie I can set it to 64GB and never have an issue.
Something else I did just to narrow anything else down was installed Citrix’s XenServer on it instead to ensure it wasn’t an XCP-ng issue and of course, same issues happened on it
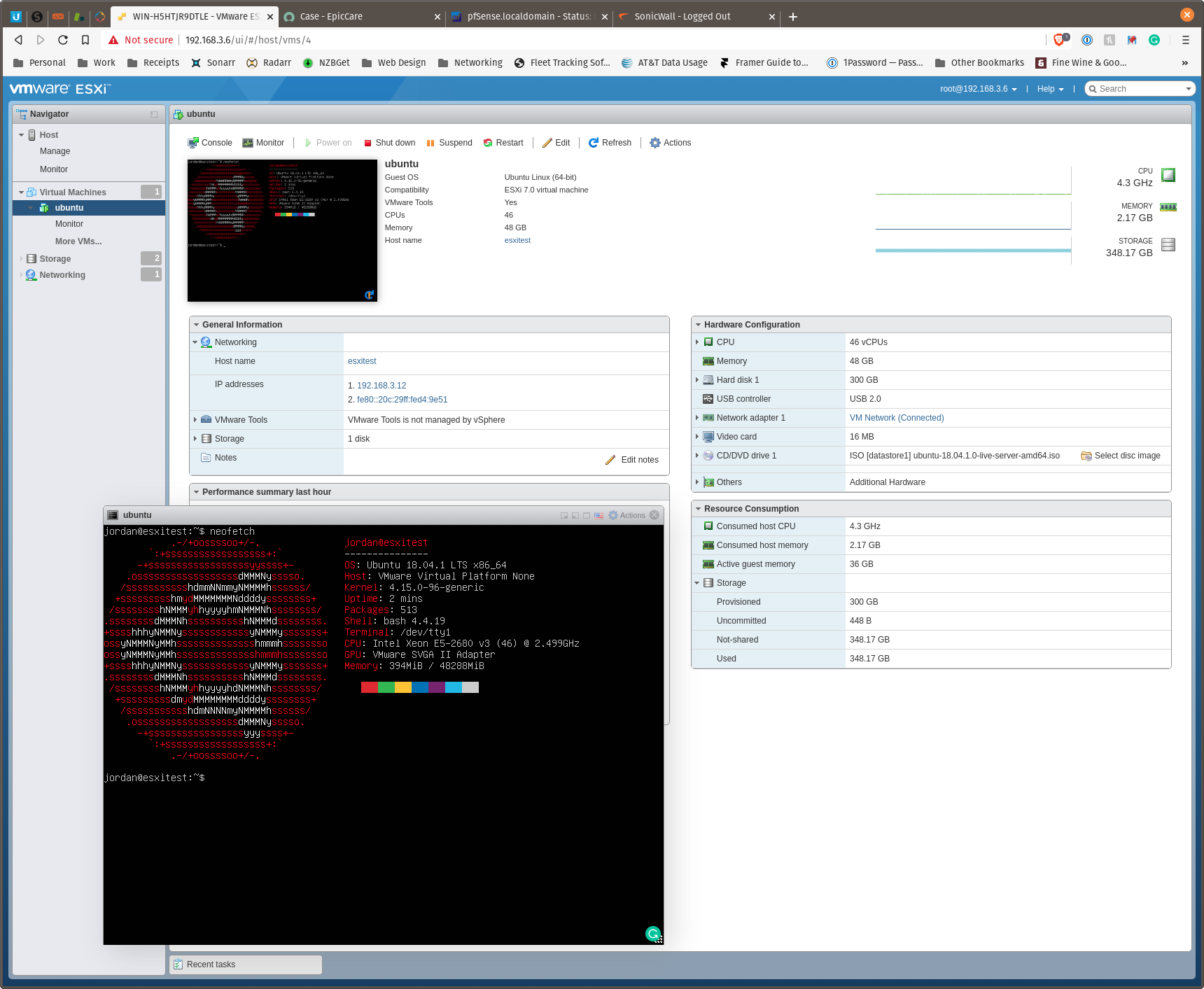
The server reported zero errors in Prime95 after running overnight. I reinstalled xcp-ng onto an SSD on the backplane with the same outcome. I installed ESXi onto the system then gave a Ubuntu VM 46cores 48GB ram, installed without and issue, rather finicky server.
Maybe ill make a new thread over on xcps forums and see if I get anywhere with the help I got on here appended, ready to replace this server with a new one.
So I had a little bit of time today to debug some more and it looks like the issue was with CPU2. Removing CPU2 everything worked fine and so i swapped CPU1 with CPU2 and left CPU2 Socket out and the issues came right back so ill run it with only 1 cpu and all of the ram on that CPU for a little to test and order a replacement CPU for Socket 2 and see what happens
I wonder how you pinned it down to the CPU. Good for you. Yet another “random” hardware issue. I’ve seen drives, RAM and now bad CPUs give random weird results. Thanks for reporting.