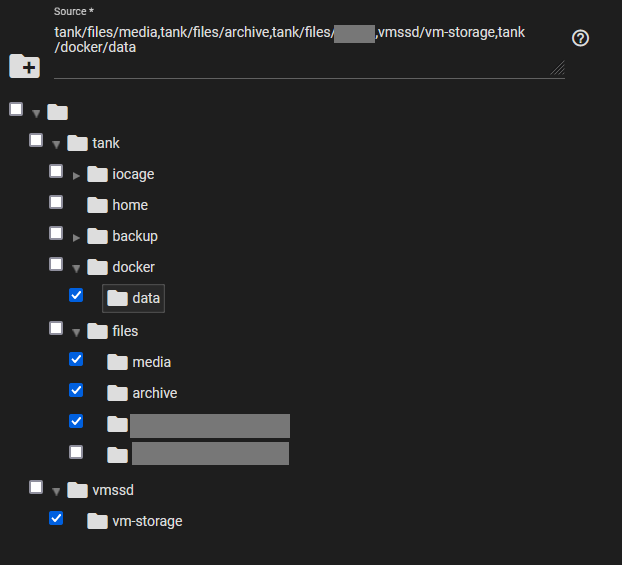
I’m currently setting up replication tasks for multiple datasets to a remote machine.
The various that are supposed to go to that target machine are not children of the same parent dataset or even pool, as shown in the picture:
Now, I could create one replication task per dataset, but I would much rather be able to do it all in one replication task (for example, If I want to change the time of day that these are replicated, I only have to do it in one place). Obviously, selecting multiple sources is possible, but what I don’t get is where these are put on the remote machine because I can only select one destination location. Can anybody shed some light on this?
These were newly created alongside the existing replicated datasets. Since I already had a couple of terabytes replicated, I zfs destroyed the newly created ones and used zfs rename to adjust the existing datasets to reflect the new structure. The existing snapshots were recognized and only the new ones had to be transferred.