I’ve been following some tutorial videos on using TrueNAS Replication Task to migrate data from an old Pool to a new Pool within the same machine. However, I’ve encountered a strange issue that I haven’t been able to resolve, and it doesn’t seem to match existing discussions, so I’m starting a new thread here for advice.
Here’s the error message I’m encountering:
warning: cannot send 'Pool_01/DatasetXXXX@Hourly_auto-2024-11-26_18-00': Input/output error
cannot receive resume stream: checksum mismatch or incomplete stream.
Partially received snapshot is saved.
A resuming stream can be generated on the sending system by running:
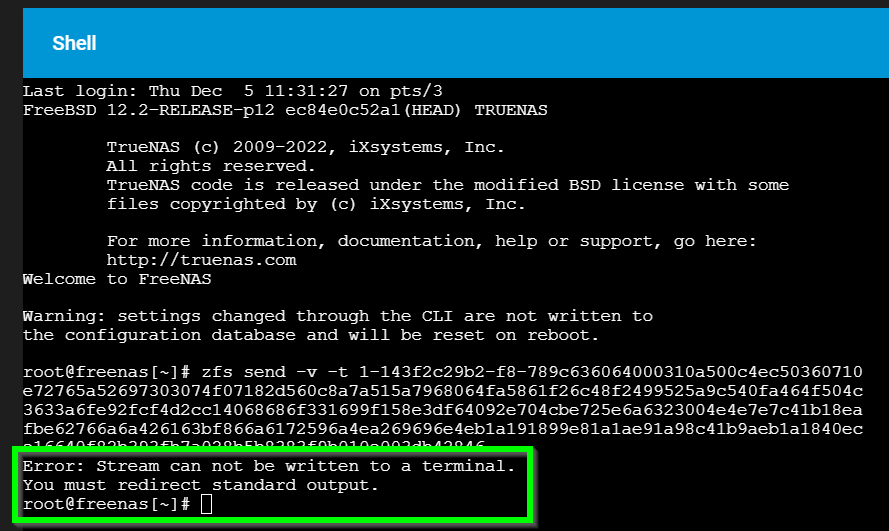
zfs send -t 1-fba22ff4e-f8-789c636064000310a500c4ec50360710e72765a52697303074f07182d560c8a7a515a7968064fa5861f26c48f2499525a9c5403aa0d2b3208b19537f497e7a69660a03c3fb56c5d5c72fc8f07820c97382e5f312735381faf3f373e20d0cf57df313335352138b1d3cf24b8b722ae3134b4bf2758d0c8c4c740d0d758dcce20d2d740d0ca0eee06640f82b393fb7a028b5b8383f9b010e00950726d7
Here are my questions:
Is there a way to specify that only the latest snapshot should be transferred? I’ve tried setting it to the Daily and Hourly snapshots, but the task keeps stopping with a similar error, leaving files updated after the date untransferred.
Should I just try to resume the task via the shell? How do I validate if everything is safely transferred?
The pool contains other datasets — is there a simple way to copy everything at once? Or is the Replication Task limited to a single dataset per task?
Could this error be a sign of an issue with my snapshots?
I’d greatly appreciate any guidance or suggestions on how to proceed.
Replication ONLY transfers the snapshots, not the current data. There is a checkbox that under replication that says “Replication from scratch” which should have the task run if there is an error or incomplete match of the data on the other side.
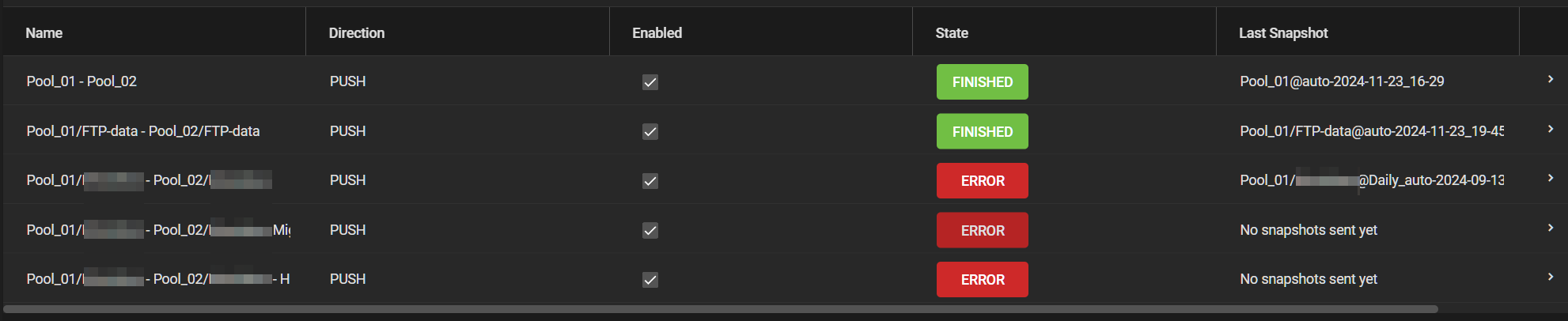
You can create a replication task for multiple data sets, but I prefer the more fine grained control of having a task for each.
Can checking this box potentially create a destructive scenario where the “error or incomplete match” is caused by a data issue on the source TrueNAS box, which then would carry over to my backup system if this is checked?
Asking because I thought it was best practice to keep this box unchecked? I am far from an expert though, just looking so make sure I am following best practices.
Thanks for the reply Tom! I did see this video, which was the first time I noticed I needed to type in the directory on the receiving side.
I am actually still on TrueNAS 12.0-U8, so I don’t see the “Replication from scratch” option. But I’ve tried the “(Almost) Full Filesystem Replication” option which still gives the same kind of error.
I also tried not specifying a naming schema to let the wizard make a new snapshot, but it keeps replicating the snapshot the wizard made last week for some reason… (that one crashed halfway due to CPU overheating)
Currently, I am running a Replication Task pointed toward a new Hourly Auto snapshot task freshly made today with a shelf life of 3 Hours, so there are only 4 snapshots that are basically the same. I’ll see how it goes and report back tomorrow.
I have never had that happen, but if you are worried that there is a problem with the source you should run a scrub. Everytime I have had to check that box it’s because thre is a problem with the destination.
warning: cannot send 'Pool_01/DatasetXXX@Migrate-auto-2024-12-04_17-00': Input/output error
cannot receive resume stream: checksum mismatch or incomplete stream.
Partially received snapshot is saved.
A resuming stream can be generated on the sending system by running:
zfs send -t 1-143f2c29b2-f8-789c636064000310a500c4ec50360710e72765a52697303074f07182d560c8a7a515a7968064fa5861f26c48f2499525a9c540fa464f504c3633a6fe92fcf4d2cc14068686f331699f158e3df64092e704cbe725e6a6323004e4e7e7c41b18eafbe62766a6a426163bf866a6172596a4ea269696e4eb1a191899e81a1ae91a98c41b9aeb1a1840ece16640f82b393fb7a028b5b8383f9b010e003db42846
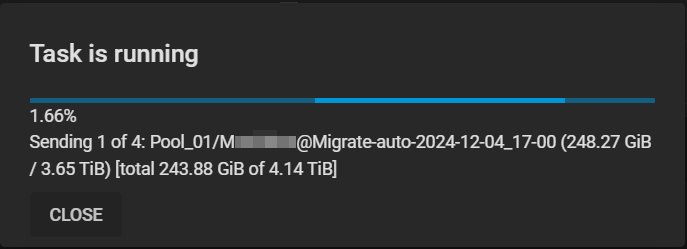
And I’ve woken up the same error message. It seems to have transferred 3TB out of 4TB and then stopped due to the error. I successfully transferred smaller datasets, but the main data storage is causing difficulties.
I’ve also tried following the error message to resume the stream, but not sure how it is supposed to work. I am considering going to rsync or fastcopy at this stage…
The target is a brand new pool, and I deleted the dataset on the receiving side to start fresh each time. I can delete the entire pool if it helps, as we’ve not started using it for production yet.
I’ve included the logs below, maybe someone can make sense of it:
Logs of the error
[2024/12/04 20:54:37] INFO [replication_task__task_6] [zettarepl.replication.run] For replication task ‘task_6’: doing push from ‘Pool_01/DatasetXXX’ to ‘Pool_02/DatasetXXX’ of snapshot=‘Migrate-auto-2024-12-04_17-00’ incremental_base=None receive_resume_token=None encryption=False
[2024/12/05 02:36:59] WARNING [replication_task__task_6] [zettarepl.replication.run] For task ‘task_6’ at attempt 1 recoverable replication error RecoverableReplicationError(“warning: cannot send ‘Pool_01/DatasetXXX@Migrate-auto-2024-12-04_17-00’: Input/output error\ncannot receive new filesystem stream: checksum mismatch or incomplete stream.\nPartially received snapshot is saved.\nA resuming stream can be generated on the sending system by running:\n zfs send -t 1-fdf8fc019-f8-789c636064000310a500c4ec50360710e72765a52697303074f07182d560c8a7a515a7968064fa5861f26c48f2499525a9c5405ac22230269b19537f497e7a69660a0343c3f998b4cf0ac71e7b20c97382e5f3127353191802f2f373e20d0cf57df313335352138b1d7c33d38b124b5275134b4bf2758d0c8c4c740d8d740d4ce20dcd750d0c20f6703320fc959c9f5b50945a5c9c9fcd0007009dd72731”)
[2024/12/05 02:36:59] INFO [replication_task__task_6] [zettarepl.replication.run] After recoverable error sleeping for 1 seconds
[2024/12/05 02:37:01] INFO [replication_task__task_6] [zettarepl.replication.run] Resuming replication for destination dataset ‘Pool_02/DatasetXXX’
[2024/12/05 02:37:01] INFO [replication_task__task_6] [zettarepl.replication.run] For replication task ‘task_6’: doing push from ‘Pool_01/DatasetXXX’ to ‘Pool_02/DatasetXXX’ of snapshot=None incremental_base=None receive_resume_token=‘1-fdf8fc019-f8-789c636064000310a500c4ec50360710e72765a52697303074f07182d560c8a7a515a7968064fa5861f26c48f2499525a9c5405ac22230269b19537f497e7a69660a0343c3f998b4cf0ac71e7b20c97382e5f3127353191802f2f373e20d0cf57df313335352138b1d7c33d38b124b5275134b4bf2758d0c8c4c740d8d740d4ce20dcd750d0c20f6703320fc959c9f5b50945a5c9c9fcd0007009dd72731’ encryption=False
[2024/12/05 02:37:04] ERROR [replication_task__task_6] [zettarepl.replication.run] For task ‘task_6’ unhandled replication error ExecException(255, “warning: cannot send ‘Pool_01/DatasetXXX@Migrate-auto-2024-12-04_17-00’: Input/output error\ncannot receive resume stream: checksum mismatch or incomplete stream.\nPartially received snapshot is saved.\nA resuming stream can be generated on the sending system by running:\n zfs send -t 1-143f2c29b2-f8-789c636064000310a500c4ec50360710e72765a52697303074f07182d560c8a7a515a7968064fa5861f26c48f2499525a9c540fa464f504c3633a6fe92fcf4d2cc14068686f331699f158e3df64092e704cbe725e6a6323004e4e7e7c41b18eafbe62766a6a426163bf866a6172596a4ea269696e4eb1a191899e81a1ae91a98c41b9aeb1a1840ece16640f82b393fb7a028b5b8383f9b010e003db42846\n”)
Traceback (most recent call last):
File “/usr/local/lib/python3.9/site-packages/zettarepl/replication/run.py”, line 164, in run_replication_tasks
retry_stuck_replication(
File “/usr/local/lib/python3.9/site-packages/zettarepl/replication/stuck.py”, line 18, in retry_stuck_replication
… 12 more lines …
self.replication_process.wait()
File “/usr/local/lib/python3.9/site-packages/zettarepl/transport/local.py”, line 164, in wait
self.async_exec.wait()
File “/usr/local/lib/python3.9/site-packages/zettarepl/transport/async_exec_tee.py”, line 103, in wait
raise ExecException(exit_event.returncode, self.output)
zettarepl.transport.interface.ExecException: warning: cannot send ‘Pool_01/DatasetXXX@Migrate-auto-2024-12-04_17-00’: Input/output error
cannot receive resume stream: checksum mismatch or incomplete stream.
Partially received snapshot is saved.
A resuming stream can be generated on the sending system by running:
zfs send -t 1-143f2c29b2-f8-789c636064000310a500c4ec50360710e72765a52697303074f07182d560c8a7a515a7968064fa5861f26c48f2499525a9c540fa464f504c3633a6fe92fcf4d2cc14068686f331699f158e3df64092e704cbe725e6a6323004e4e7e7c41b18eafbe62766a6a426163bf866a6172596a4ea269696e4eb1a191899e81a1ae91a98c41b9aeb1a1840ece16640f82b393fb7a028b5b8383f9b010e003db42846
I came across a similar discussion last night, so I just scheduled a scrub on the source.
It was completed this morning and displayed “Scrub repaired 0B with 2 errors.” It also listed the two problematic files. Could you advise on how best to handle these? Should I overwrite the files or delete them?
Additionally, I followed the method from this video by Craft Computing to verify file lengths and timestamps using Windows dir and fc commands. Here’s the process:
Mount the new pool as the Z: network drive and run the following command:
Z:\> dir /s > DirNew.txt
Then, remount the old pool as Z:, restart CMD, and run the same command:
Z:\> dir /s > DirOld.txt
Finally, I compared the two files locally with the following command:
K:\Temp> fc DirOld.txt DirNew.txt > output.txt
The output.txt file highlighted many differences, but they were all related to Thumbs.db or temporary .xlsx or .docx files. Are those skipped automatically by rsync ?
With this, I believe everything is in place and verified!
Except for the 2 files that the scrub failed to fix, they were recovered from someone’s PC, so it’s still fine.
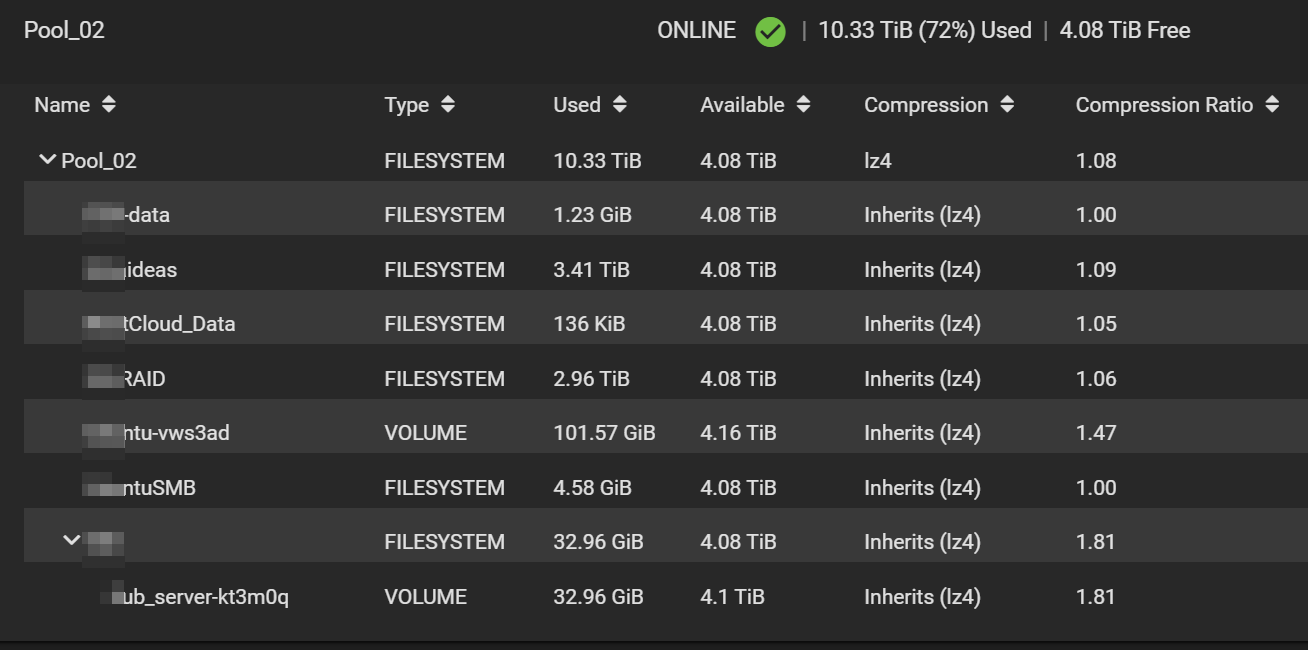
After moving & verifying the files today, I noticed that the available space on Pool_02 is significantly less than I expected. The total used space on the transferred datasets adds up to only about 7TB, but the entire pool shows 10TB as used.
I checked for snapshots, and while there were some created earlier due to zfs send, I’ve deleted them all over the past two weeks. No auto snapshot tasks have been initiated on the new pool either.
Could anyone help me understand where the missing space might have gone?
Any insights would be greatly appreciated!