Not really asking for help – this is more like a project or a build log (if you can call it that, of sorts).
Set up the 3-node Proxmox cluster about 4 hours ago. That took a little bit because the Proxmox 8.2 installer wouldn’t boot up with my 3090 installed in my 5950X system, so I had to swap it out with a GTX 660 instead, to get the install going. (5950X doesn’t have an iGPU, hence the need for a dGPU.)
The 7950X is a Supermicro AS-3015I-A “server”, which also uses the Supermicro H13SAE-MF motherboard, so it has built-in IPMI, so no dGPU was needed for that.
Two nodes are 5950Xes, one 7950X.
They all have 128 GB of RAM (DDR4, DDR4, DDR5 respectively) and Silicon Power US70 1 TB NVMe 4.0 x4 SSD for the 5950X systems, and an Intel 670p 2 TB NVMe 3.0 x4 SSD in the 7950X.
All of them have a Mellanox ConnectX-4 dual port VPI 100 Gbps Infiniband NIC (MCX456A-ECAT) in them, connected to a Mellanox 36-port externally managed Infiniband switch (MSB-7890). My main Proxmox server is running the OpenSM subnet manager that ships with Debian.
Got that clustered up over IB.
And then installed Ceph Quincy 17.2 and got the erasure-coded pools up and running.
I can live-migrate a Win11 VM (with 16 GB of RAM provisioned to it) in 21 seconds after learning how to make it use a specific network for the live migration.
edit
I can live-migrate an Ubuntu 24.04 VM (which also has 64 GB of RAM provisioned to it) in 10 seconds at an average migration speed of 12.8 GiB/s (102.4 Gbps)
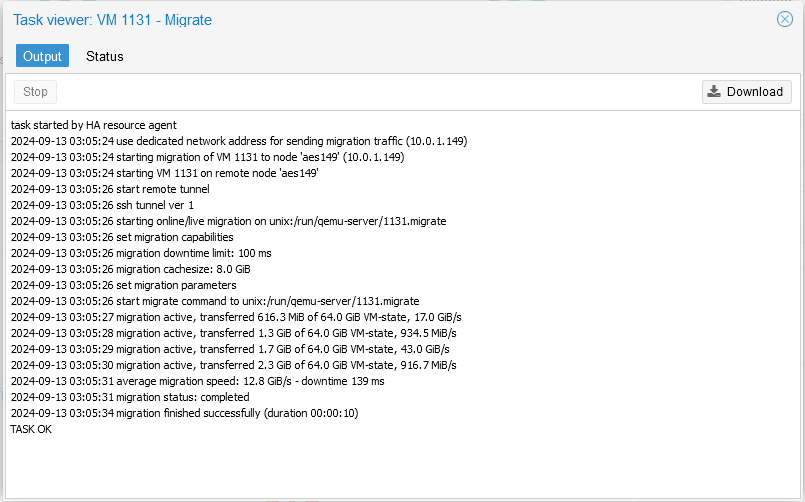
edit #2
Here is a live migration of a Win11 VM with 64 GiB of RAM provisioned to it. (16 GiB/s = 128 Gbps)
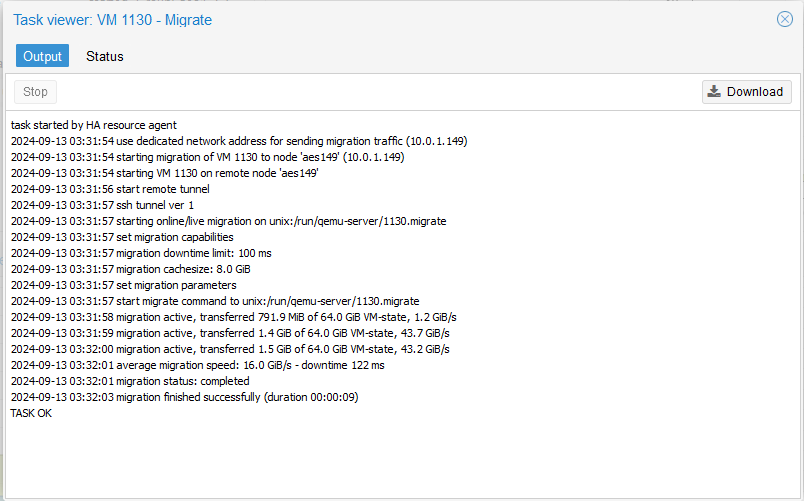
edit #3
Three things:
-
In late testing last night/early this morning – I did manage to hit a peak of 16.7 GiB/s (i.e. 133.6 Gbps) during a live migration of the Win11 VM. (I also set up an Ubuntu 24.04 VM to play with live migration as well, and got basically the same speeds.)
-
Live migrating from the 7950X to the 5950X is where I can hit these speeds. Live migrating where the source comes from the 5950X node(s), tended to peak out at around 11.1 GiB/s (88.8 Gbps).
So, it’s kind of crazy (which NO ONE has tested, nor talked about) how the generational improvement from 5950X to 7950X can result in upto a 33.5% bandwidth improvement for high speed system interconnect communications.
The Mellanox ConnectX-4 cards are only PCIe 3.0 x16 cards, so the fact that the 5950X has PCIe 4.0 and the 7950X has PCIe 5.0 – is completely irrelevant here. The NIC can’t use the newer PCIe generations.
Which means that even when limited by PCIe 3.0, the 7950X is STILL faster than the 5950X.
- The amount of RAM that has been provisioned to the VM makes a difference.
Originally, the VMs only had 16 GB, and so, the migration cachesize appears to be set to be 1/8th of that (so 2 GB), which meant that at best, I was only getting like maybe 5-6-ish GB/s during said live migrations. It was difficult to push much further beyond that.
But when I bumped the RAM up to 64 GB, the migration cachesize window (still being 1/8th of the RAM) now opened up to 8 GB, and this is where I started seeing these significantly faster live migration speeds. (I didn’t spend a lot of time studying the effect of RAM size to migration speed.)
I tried this morning, bumping that up to 100 GB of RAM, and that actually ended up being slightly slower at 14-ish GiB/s. Still decent and respectable, but it looks like that it was just a little further, as that’s still ~112 Gbps.