I set up a new test server using an Intel Core i5 6500T, 16 GB of RAM, and 4x HGST 1 TB SATA 6 Gbps 7200 rpm HDDs.
I installed TrueNAS Scale 24.04.2 on one of the 1 TB HDDs, and the remaining HDDs are in a 3-wide raidz pool.
I also set up an Ubuntu VM on it (which was an adventure unto itself as it’s not quite as straightforward as Proxmox, but I digress), and I set up ZFS snapshots to take a snapshot every hour, on the hour, and to keep it for a week.
So whilst the VM is sitting idle, and whilst I’m at work, the system is still taking the snapshots, despite there being no activity nor change in data in the VM itself (because it isn’t doing anything but helping me move some files between my main Proxmox server and this new server that I’ve set up).
So, my question is how do I calculate how much space I need to provision extra, for the storage of the snapshots?
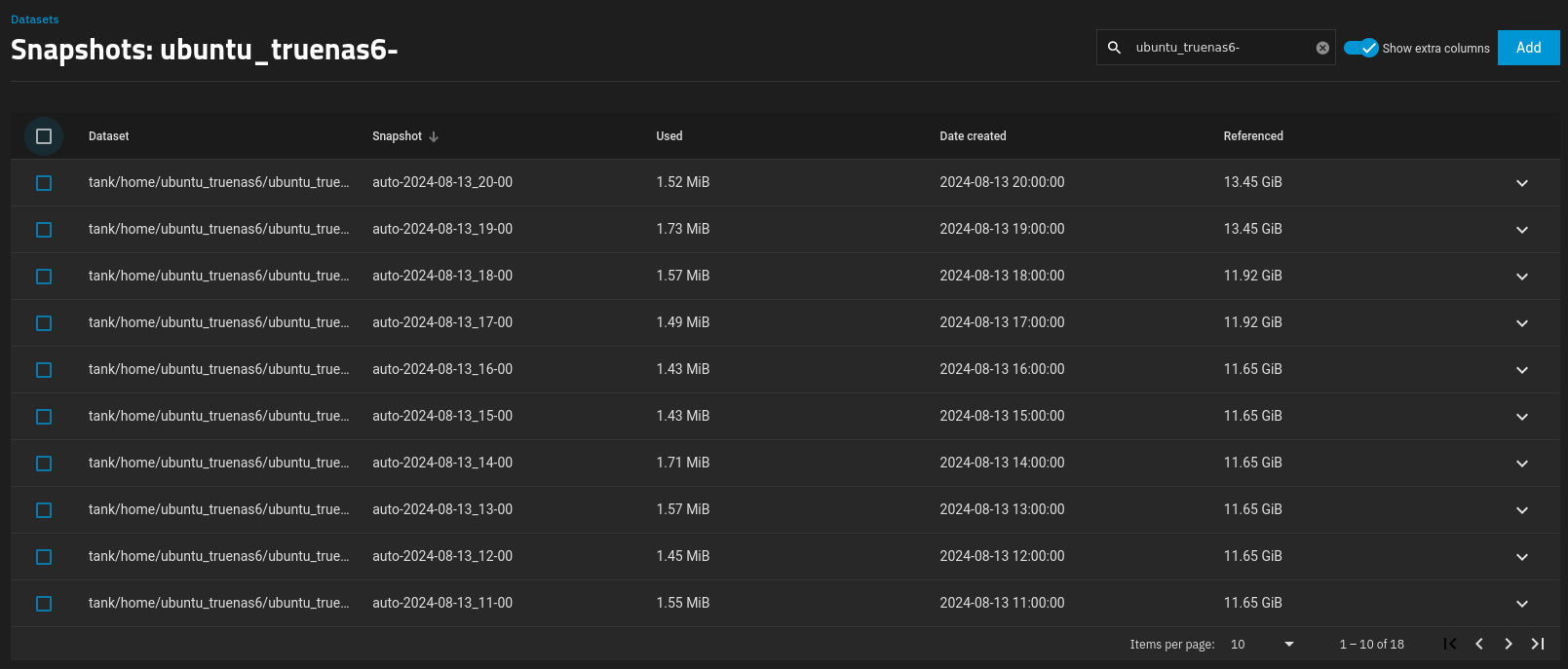
I can see that right now, each delta snapshot is about 1.7 MiB or so, but what I am wondering is if there is a way to calculate or predict/estimate what that additional storage space requirements/needs are, even if a VM is doing nothing?
Your help is greatly appreciated.
Thank you.
(Sidebar/background: I am running this test because what I am ACTUALLY interested in testing is to see what happens to the data when the snapshots gets automatically pruned based on the retention policy that I’ve set.)
But it doesn’t explain how I can predict how much space the deltas will need, given that nothing in the underlying data has changed.
i.e. My Ubuntu 22.04 VM is literally right now, sitting there, doing NOTHING, and ZFS still think that there is about 1.7 MiB of data that’s being changed, with NOTHING running (except it’s sitting idle, at the desktop).
According to the video above, I would have expected the delta to be 0 Bytes (because nothing is changing), and yet, that’s not the case.
So, how I can predict how much extra space I am going to need, for the snapshots/deltas?
edit #1
(I have one Firefox browser tab/window open on the 7z(1) man page from linux.die.net and then two terminals windows open (but also idle) and one window of the graphical file explorer, but also sitting idle. And somehow, with the VM doing nothing, ZFS thinks that it has about 1.7 MiB worth of data delta. The video above doesn’t talk about how you could’ve possibly estimated/predicted this 1.7 MiB delta (per hour), given what the VM is, and isn’t doing.)
“Additionally, deleting snapshots can increase the amount of disk space unique to (and thus used by) other snapshots.”
Therefore; given the two combined, it would mean that in theory; if I didn’t set an automatic retention policy of the snapshots, it would’ve gained 1.7 MiB per hour, every hour; until my pool ran out of space, basically.
And that deleting the snapshots won’t actually free up any space because as it states in said ZFS Administration Guide, deleting the snapshot will just mean that the space delta between the snapshot will increase proportionally.
So, if I have three snapshots, A=1.7 MiB, B=1.7 MiB, C=1.7 MiB, according to the ZFS Administration Guide, deleting snapshot B would just mean that A=1.7 MiB, and C will now be 3.4 MiB in size. (1.7 MiB from B + 1.7 MiB from C).
I’ve asked/commented on Tom’s video before and it doesn’t really explain how that works.
Based on the observed behaviour, without an automatic retention policy, it will just grow and grow and grow, indefinitely, until your ZFS pool runs out of space.
No, once you delete the oldest snapshot that will free up space. If you do not have snapshots that auto delete then yes there is a limit based that will be reached based on how much space you use. Worth noting that simply rebooting a VM will cause it to make a few changes in log files that will use space.
@LTS_Tom
Thank you for educating me about how the space calculation should work, in regards to the snapshots getting deleted.
The VM has been up for about 2 days, 19–almost 20 hours.
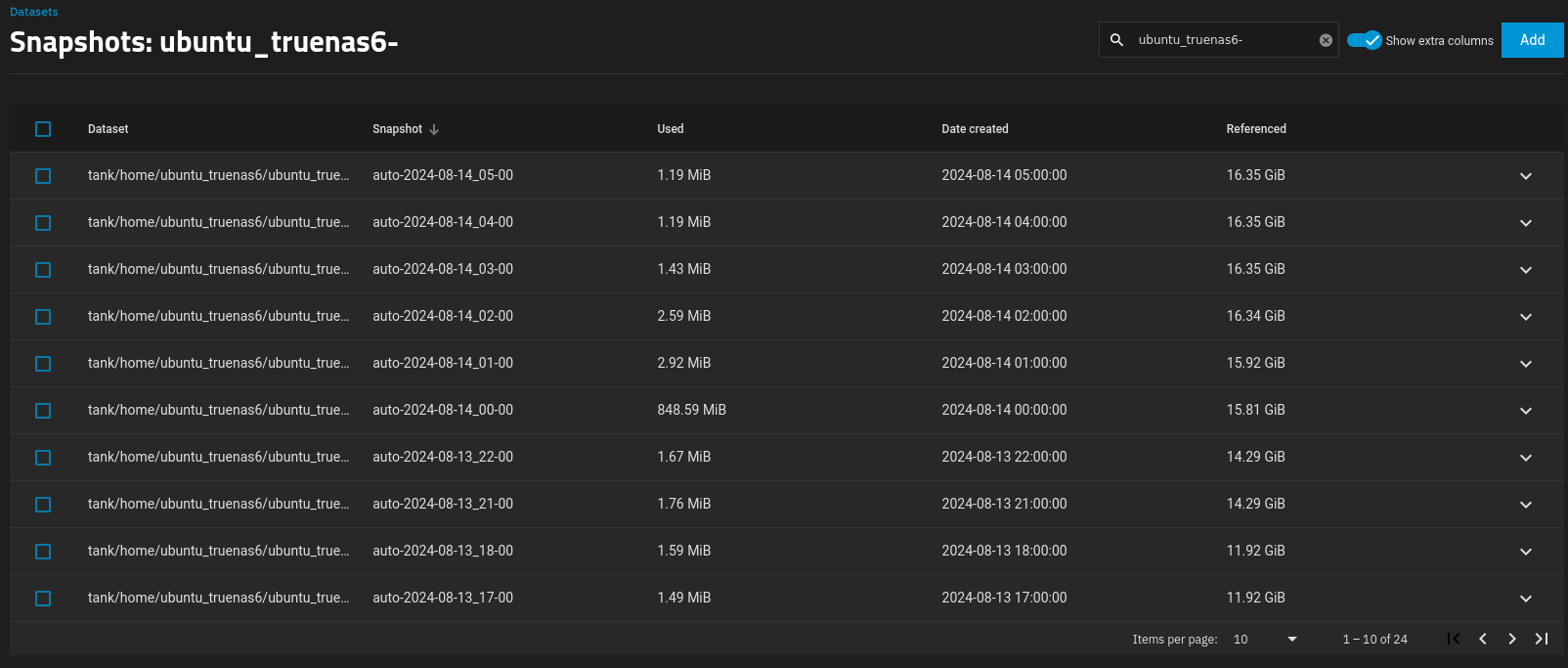
Each hourly delta snapshot is now about 1.2 MiB.
I would agree and understand that if the VMs were rebooting, that would be a cause for the incremental snapshot delta; but given the 2 day 20 hour uptime, that would suggest that there hasn’t been any reboots since the VM were brought up online which would explain the hourly incremental snapshot delta.
So I’m still a bit at a loss as to why an idle Ubuntu 22.04 VM would produce a ~1.2 MiB hourly incremental/delta snapshot.
And I reckon that this is something that if you want to test, it is quite easy to replicate.
Download the Ubuntu 22.04 desktop installer ISO.
Select “Try Ubuntu (safe graphics)” when GRUB comes up in the VM.
Run through the install.
Update Ubuntu and then let it sit.
With the hourly snapshots configured, you can watch it take the snapshots where it will report that ~1.something-ish MiB of data has changed, whilst said VM sits idle.
edit
Also, supposed that you created the 1.7 MiB text file and the snapshot captured this delta in the snapshot.
So, hourly snapshot A=A.txt, which is 1.7 MiB, hourly snapshot B=B.txt, which is also 1.7 MiB, and hourly snapshot C=C.txt, 1.7 MiB - you delete snapshot B – does that mean that you also delete B.txt along with deleting that snapshot?
I would imagine that the current state of the VM, at that moment, still has A.txt, B.txt, and C.txt.
Would this mean that houly snapshot D will contain not only D.txt (1.7 MiB), but also B.txt (1.7 MiB)?
How do you get ths space back if hourly snapshot D will just end up being 3.4 MiB in size (2*1.7 MiB for B.txt and D.txt)?
I’m not sure that I fully understand how the space works, which leads back to my question of how do you predict/estimate how much extra space you need to provision above the space taken by your actual data itself?
And then Linux fanbois et. al. wonder why the general population, outside of Linux enthusiasts, either don’t use Linux (at best) or absolutely hate it (at worst) – it’s because of responses like this that does nothing to actually answer the question at hand.
(If you’re going to provide an useless answer, the least that you can do is actually answer the original question first, and then you can provide whatever other superfluous fluff, ex post facto.)
Sounds to me like you either don’t know why an idle system will generate ~1.2-1.7-ish MiB of data or you’ve never actually bothered to look. Either way, the result is the same: you can’t answer this question about the logic with any meaningful explanation, supported with data and evidence.
The answer is a non-answer as it never actually explains why there’s an hourly ~1.7-ish MiB delta in the first place.
Can’t dislike an answer that doesn’t actually exist.
The real answer, so far, is that none of the proponents nor users of TrueNAS Scale/ZFS knows nor understands why. And if I were to guess, it’s also because you’ve never studied the matter neither, so that you can answer the question “how much extra space do I need to plan for, when I am building out a NAS server? (so that it will have space for the snapshots)”
Is that how you operate at your work, where when you don’t know the answer to a question, you just throw money at it?
Your IT Director tells you to put together a proposal for a storage server, and you need to tell them how many hard drives you’re buying and why, but given that you don’t know how much extra space you will need for all of your snapshots, you’re just going to throw out a number with little to no evidence to support your cost estimate?
(Because if you can buy it to try it out, then you would’ve already spent at least some money buying it so that you can try it out.)
And that’s the thing – you couldn’t have assumed that an idle system would be consuming additional storage space, let alone how much extra it was going to consume.
I’ve already done both.
And that’s on top of the fact that I am neither a programmer nor a developer.
(Funny how that’s your answer to this question, where you make the implicit assumption that anybody can read and understand code, when reality can’t be any further from that theory/statement. Most people don’t read nor understand code.)
Since you talk about making general assumption – here’s one:
CIA code is NOT just in Ubuntu systems.
It’s in ALL Linux systems.
There. Tada!
(Always interesting that people who can’t answer a question, but also can’t stay silent, will have to speak even when they have nothing to contribute.)
Snapshot A records the state of the filesystem at a certain time. Let’s say Snapshot A is 1.7 MiB in size.
Second Snapshot (B):
Snapshot B is taken at a later time, recording the changes made since Snapshot A. If no changes occurred, B might take up very little additional space. However, for this example, we assume Snapshot B is also 1.7 MiB.
Third Snapshot (C):
Snapshot C is taken even later, recording changes made after B. Again, let’s say it’s 1.7 MiB.
Deleting a Snapshot (B):
Before Deletion:
A: 1.7 MiB
B: 1.7 MiB
C: 1.7 MiB
After Deletion:
When you delete Snapshot B, ZFS has to reconcile the changes that B was tracking, so that the file system remains consistent. The data that was unique to B and not present in A or C must be preserved.
ZFS essentially merges the data from Snapshot B into Snapshot C. As a result, Snapshot C now includes the data from both B and C.
Sizes After Deletion:
A: 1.7 MiB (remains unchanged)
C: 3.4 MiB (1.7 MiB from B + 1.7 MiB from C)
How Does This Work?
Data Deduplication: ZFS doesn’t store multiple copies of the same data. When you take a snapshot, ZFS tracks the blocks that change. If Snapshot B is deleted, ZFS merges the changes that B was tracking into the next snapshot (C).
Space Reclamation: The space that was uniquely tied to Snapshot B doesn’t vanish but is absorbed into Snapshot C. This is why the size of Snapshot C grows to include the changes from B.
Efficient Storage: ZFS ensures that the file system’s integrity and history are maintained while minimizing storage use by only storing the differences between snapshots.
In summary, when you delete Snapshot B, the data that B was uniquely tracking is not lost but gets transferred to the next snapshot (C). This explains why Snapshot C’s size increases after B is deleted.
I appreciated the detailed breakdown and explanation in regards to the accounting of the space and is consistent with the Oracle ZFS Administration Guide, based on how I have read and interpreted said admin guide.
Therefore; pursuant to Tom’s comment about that the space would be freed by deleting the snapshot – that’s only half correct, isn’t it?
(i.e. yes – the space that was occupied by snapshot B would be freed, HOWEVER; the space that will need to be taken up by snapshot C would increase proportionally, therefore; overall, you’re at a net 0 space difference, correct? (because you’d free up the 1.7 MiB taken up by snapshot B, but then you’d increase the space that would be taken up by snapshot C (up from 1.7 MiB to 3.4 MiB), therefore; resulting in a net 0 Bytes pool space savings.)
Following that logic – wouldn’t that mean then, that the space consumed will perpetually grow, even with the retention policy in place where it will automatically delete/prune old snapshots away, based on this delta-based calculation?
i.e. suppose that you have snapshots 1-100, and then you have snapshots 101-200, and you’re about to write the next 100 snapshots. (Technically, it would be 168 snapshots because I am writing them hourly, but I am going to skip over that for the moment to make the worked example math a little bit easier, conceptually)
You wrote the first hundred snapshots at 1.7 MiB a piece, for a total space consumed of 170 MiB.
You wrote the next hundred snapshots at 1.7 MiB a piece, for a total space consumed of 170 MiB.
(You’re upto 340 MiB total at this point.)
As you are about to write your 201st snapshot, you delete snapshots 101-200, thus you’d “free up” 170 MiB of space.
However, because of the delta that exists, the 201st snapshot would take up a nominal delta of 1.7 MiB. But now you need to add the delta that arose as a result of deleting snapshots 101-200, which means that 170 MiB from the second group of 100 snapshots will now be added to the 201st snapshot, making snapshot201 = 1.7 MiB + 170 MiB = 171.7 MiB.
And then snapshots 202-300 will still be 1.7 MiB each or a cumulative total of 168.3 MiB (170 MiB - 1.7 MiB).
Therefore; in the end, snapshots 1-100 = 170 MiB, snapshots 101-200 = {} (deleted), snapshot 201=171.7 MiB, and snapshots 202-300=168.3 MiB (which would still be 170 MiB + 170 MiB + 170 MiB = 510 MiB).
Therefore; deleting a snapshot – you’re never actually saving any space, pursuant to your detailed explanation.
Which means that from a disk space provision perspective, the space that the snapshots take will grow infinitely and indefinitely.
Please check my math to see if what I just wrote makes sense.
I took the example of the 3 snapshots (A, B, C) and extended the application of the theory to cover 100 snapshots in each “group” of snapshots.
And then you can extend this theory to n-number of snapshots, and then you can scale this, indefinitely, upto the frequency of the taking of the snapshots (albeit if you took a snapshot every minute, then the size of each snapshot won’t be 1.7 MiB anymore, but again, I recognise this, but I also digress…).
And this is just for an idle VM, let alone a working one.
And yes, I am purposely using an idle VM because I actually don’t need the VM to do anything (I have my main Proxmox server and also my 3-node HA Proxmox cluster for actual work/stuff that I need the VM/LXC containers to do the actual work), so I am using this to test how the space reconiliation (and therefore; the space provisioning aspect) works.
Maybe if you ran an experiment so you could get a better idea on how this works. Maybe setup an Ubuntu VM with zfs or install truenas on a VM. Create a pool and then create a dataset and then add some data to it. Snapshot it and then change the data and then snapshot again. Check it with this command
Change the dataset_name to the dataset that you snapshot zfs list -r -o space,refer,written -t all tank/dataset_name | head -20
Delete the snapshot you want and then run the command above to check how much is used.
Minus the TruenAS in a VM, that’s basically what I’ve done here, as detailed above.
(I’m running TrueNAS Scale, on bare metal, with an Intel Core i5 6500T, 16 GB of RAM, Gigabyte H110-D3A, and 4x HGST 1 TB SATA 6 Gbps HDD, with no discrete graphics, and a Corsair CX750 750 W PSU. TrueNAS Scale is installed on one of the HGST 1 TB drives (because apparently that motherboard only supports M.2 SATA drives, despite calling the slot a NVMe slot, and has a NVMe option in the BIOS. But I digress.)
I created the ZFS pool tank and then created the dataset test (which is set up as a NFS and SMB share). Then I created a 256 GiB zvol (which is used as a iSCSI extent), and then created a dataset for the Ubuntu VM (so that I can impose quota limit on that dataset of 41 GiB).
The Ubuntu VM disk is 32 GiB (hence why the quota on the dataset is 41 GiB because TrueNAS Scale won’t let me create the disk on the dataset which uses 80% of the quota).
At ~1.7 MiB/hour snapshot space consumption, that works out to be about 40.8 MiB/day, and with a snapshot retention policy set for 1 week, that means that it will consume 285.6 MiB/week. Therefore; to see whether the growth of the space requirement would be infinite (basically), at the end of the 8th day, if the space consumed remained at 285.6 MiB, then the deleting of the snapshot and the recovery of the space follows what Tom said earlier.
However, if the space consumed at the end of the 8th day is 326.4 MiB (i.e. 285.6 MiB + 40.8 MiB), then this means that what you wrote earlier holds true, and therefore; the space requirement grows infinitely, due to the way that the next snapshot accounts for the delta from the prior snapshot meaning that you will never free up any space from deleting the snapshot.
Furthermore, what’s also weird is that on an idle Ubuntu VM, where no active changes are being made to said idle Ubuntu VM, the snapshots is still recording 1.7 MiB in changes, and nobody seems to have any explanation that would account for this behaviour.
I understand that if you were making active changes to the VM, then sure, you can and should expect there to be deltas in terms of the space consumption as a result of what you’re doing inside the VM.
But that isn’t the case here.
I have purposely left the Ubuntu VM at idle, because what I am testing is the snapshotting behaviour, and NOT the Ubuntu VM itself.
So the fact that an idle Ubuntu VM, according to ZFS, is recording 1.7 MiB of changes, where there are no active changes happening to nor inside said idle Ubuntu VM – I dunno about you, but to me, that defies logic.
And given that nobody here seems to be able to explain why I am seeing what I am seeing, I surmise that it is defying the logic of others in this forum as well since nobody has been able to offer any explanation as to why it is recording 1.7 MiB of changes to an Ubuntu VM that has no active changes.
So…at the current rate of about 285.6 MiB/week, it’s going to take a while to eat up 9 GiB of extra space in the dataset that was created for the Ubuntu VM. (on the order of about 31 weeks)
If the delta that’s being recorded DROPS, then the time it will take will extend correspondingly.
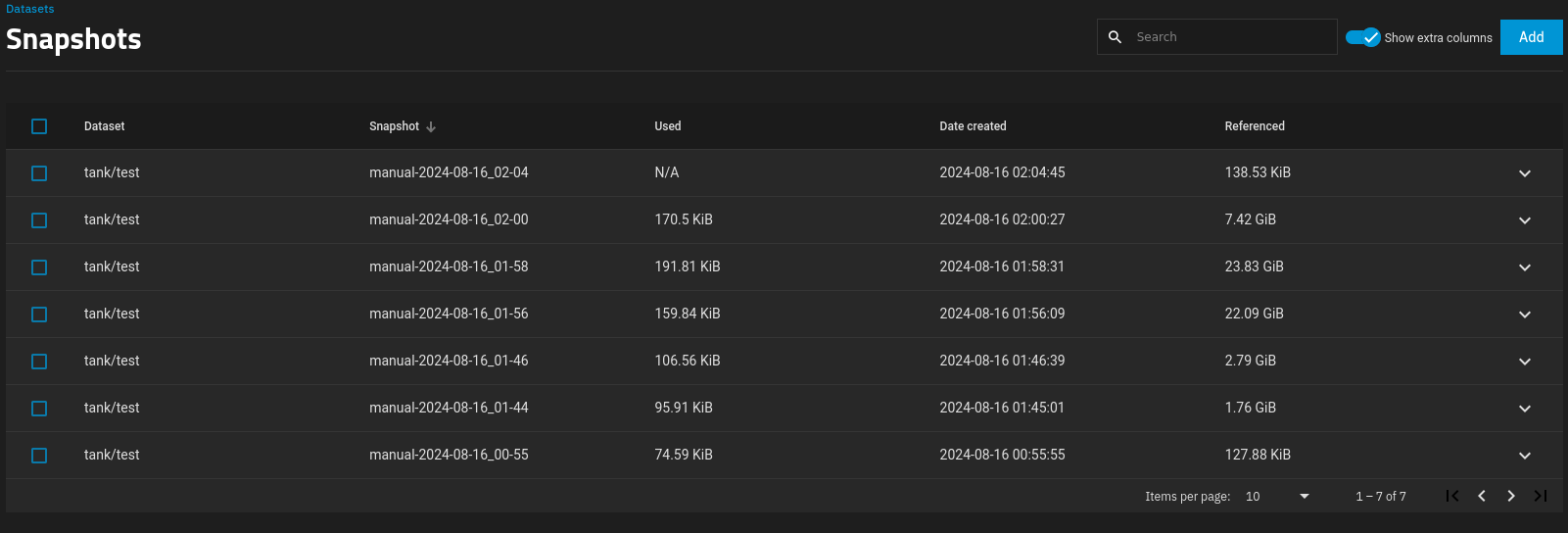
You can see that the size that is referenced increases, by quite a bit (relatively speaking), but the used delta is small compared to the delta of the referenced size.
So, here is what I did:
I tested writing a 1 GiB file, inside the VM, using this command:
dd if=/dev/urandom of=1Gfile1 bs=1024k count=1024
Did that either once every hour or two hours or so, and I also let the snapshots go for two hours, instead of one, because I wanted to see whether or not the used delta would recognise and show that there was a 1 GiB file of random data written inside the VM, and as you can see, the used delta is still only about 1.something MiB or so (e.g. going from the 1800 EST snapshot to the 2100 EST snapshot. There were other snapshots in between, but I had deleted them, per the test as indicated above, to see whether or not the theory of if you have snapshots A, B, and C, and then deleted snapshot B, then the used delta for snapshot C should be the delta between B and A plus the delta between C and B combined. However, right now, I can’t even get the delta to recognise that I had written the 1 GiB file in the first place, let alone trying to get it to calculate the delta correctly.)
And for the record, I also tried using /dev/random in lieu of /dev/urandom in the dd command above, and what you see in the after picture is the result of both, where the later snapshots are with /dev/random whilst the earlier snapshots were done with /dev/urandom.
There is only one snapshot (at 0000) where it showed the notable used delta of 848.59 MiB that was recorded by ZFS, but besides that, the rest of the snapshot deltas, even though I was still writing a new 1 GiB file every two hours, still wasn’t being recognised by ZFS.
And I also purposely didn’t use /dev/zero to avoid data compression with the ZFS delta calculation, but it would appear that it doesn’t really matter because I am having troubles, using dd to write/generate a 1 GiB file, that the used delta in the snapshots would even recognise it that there is a new, 1 GiB file, inside the Ubuntu 22.04 VM, in the first place.
So I have no idea what that’s about.
According to df -h inside the VM, the VM disk, as I mentioned above, I gave it 32 GiB, so at the start of the test, I had 18 GiB free.
Right now, it is showing 15 GiB used and 15 GiB free (out of a size of 31G, according to df), which would make sense given that I have written three 1 GiB files. (I would change the number at the end of the 1Gfile# name.)
So, I’m not really sure what’s going on here or how I can make ZFS snapshots recognise that I have written 1 GiB of data inside the VM such that it’ll show up in the used delta in the ZFS snapshots.
Any tips on what I might be able to try to make that “trip” is greatly appreciated.
So, the last group of tests, I was testing within two Ubuntu VMs that was running on the TrueNAS Scale system.
Now, I just tried to test it directly on the host system.
Using the same command: dd if=/dev/random of=1Gfile# bs=1024k count=1024
Where # is for different numbers as I am writing multiple files so that I can make it take up more space, so that I can test the “Used” field in the snapshot, to show the delta between snapshots, so that I can assess the theory of operation against reality.
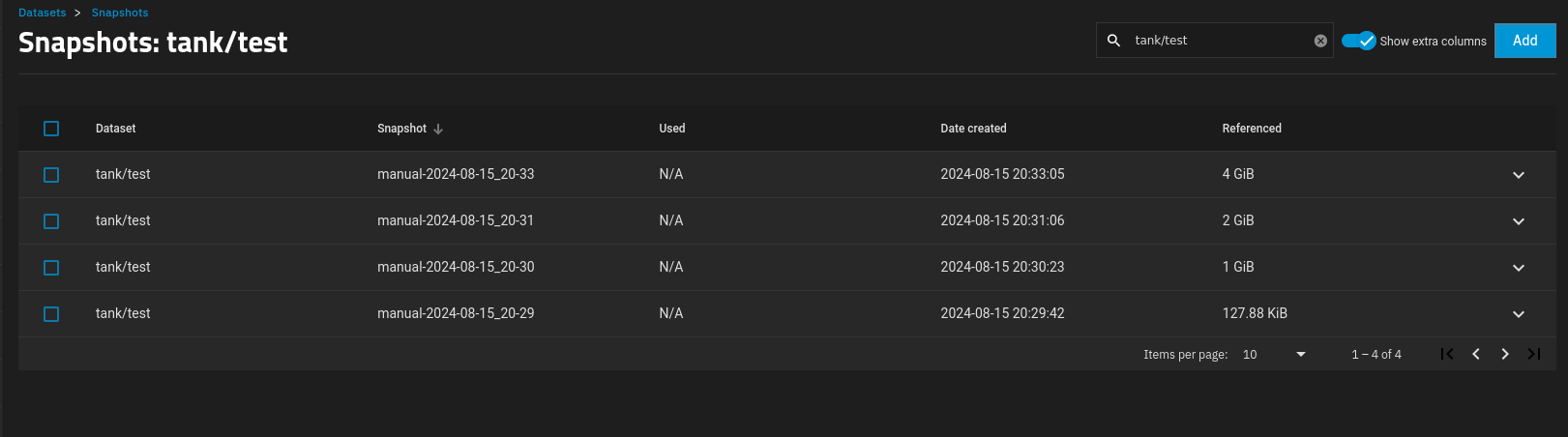
Shown above is what happened after I wrote four files, but deleted the 3rd snapshot in between.
Two things that I don’t understand:
The “used” column shows “N/A” rather than 1 GiB (the size of the file that was written). So it doesn’t appear to show nor calculate the delta per the theory of operation as described above. (And again, I am using /dev/random was to try and avoid any potential compression that may arise from using /dev/zero.)
The “referenced” grows as I write multiple 1 GiB files to the host, so that is correct.
So I don’t really understand why, when I am making changes directly on the host ZFS pool system/dataset, that the delta isn’t accurately represented with respect to the theory of operation.
I’d love to learn more about why when I write 1 GiB of data, the “Used” column doesn’t reflect that.
Thank you.
edit
Refreshed the snapshot screen, and it shows this now instead:
Note that the Used column is still only a tiny fraction of the size of the 1 GiB files that were written between snapshots.
edit #2
It doesn’t matter whether I use /dev/random or /dev/urandom – the result, from the snapshot perspective, remains the same.
#edit#3*
Just tried dumping a bunch of files (actual data files) to the host via another Ubuntu VM (because rsync, directly running on the host, was super slow for some strange reason).
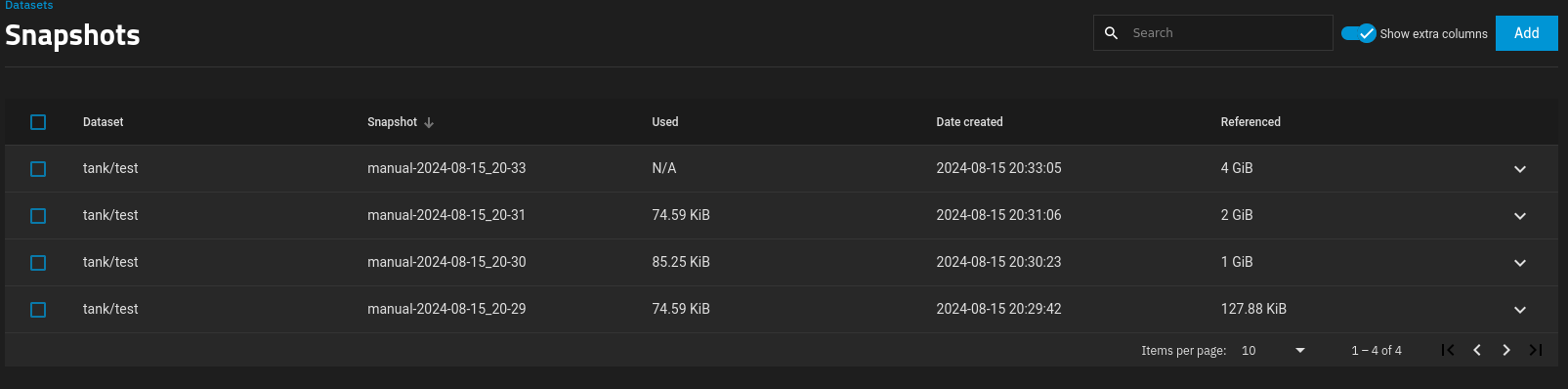
In any case, here is what the snapshots screen show:
You can see the increases then decrease in the referenced data, but the size of the snapshot is only < 200 KiB at most.
So…I have no idea how it calculates the “used” size as it isn’t anything like the theory that it accounts for the delta between snapshots (from the referenced column).
Also, deleting “in-between” snapshots also doesn’t change the used size by much at all.
So I’ve been running this experiment with snapshots and trying to see how much space it takes up for a little while now.
I have four Samsung 850 EVO 1 TB SATA 6 Gbps SSDs that are tied together in a raidz pool (managed by a TrueNAS VM, running under Proxmox 8.2.5). I have only one Win11 VM running off that pool right now, and it is set to take a snapshot hourly, with a one week retention policy.
I created the root raidz pool tank and then created a dataset test underneath that.
The snapshot is set at the zpool level (i.e. tank). I have noticed that the amount of space referenced continues to grow seemingly infinitely.
Is this normal and/or expected behaviour?
Or is this because the location where the snapshots live is the same location as the pool where the snapshots are being taken, and therefore; even as it deletes/purges the older snapshots, the newer snapshots still sees it as data that has changed, therefore; leading to an infinite growth in the referenced space?
Your help in trying to make sense of what I am seeing is greatly appreciated.
I can undestand it from the data delta perspective, that the snapshot will record what has changed, but the overall size remains relatively constant as I only gave the Win11 VM a 100 GB VM disk to work with, of which, 65.1 GB is still being reported as free space via Windows Explorer.
So in terms of total space used, it’s hovering around the 35 GB mark.
I watched the Matt Ahrens video via the link that you provided above, and in it, he talks about how if a data block (in a snapshot) isn’t referenced by something else, that it should be able to free up space.
So whilst I am seeing that the total space (in the pool, since I only have the one VM running on it and no other data), doesn’t really change (with 4x Samsung 850 EV0 1 TB SATA 6 Gbps SSDs in a raidz pool), it stays pretty constant at about 25.9% total space utilisation (which also includes a 256 GiB zvol that I am currently not using for anything yet).
But the referenced size appears to grow seemingly infinitely. I can’t imagine that being particularly good, in the long run.
Is the referenced size really supposed to grow like that?
We have lots of production TrueNAS systems not only in our office but ones we maintain for clients and I have never really spent that much time thinking about the small changes and have a system run out of space with a mostly constant grow rate from logs.