Hi all,
Thank you to anyone who responds and takes time to read my post. I have a TrueNAS Scale system that I’ve been running for nearly 3 years with no issues at all. First a quick breakdown of my system:
- ASRock X570M Pro4 M-ATX motherboard
- Ryzen 9 3950X (in ECO Mode)
- 64 GB of Kingston ECC RAM
- 6 8TB HGST Ultrastar He8 (HUH728080ALE601) drives for storage
- 2 Intel 240 GB SSD for boot
- 2 Intel P1600X 118 GB Optane Drives for SLOG
- TrueNAS Scale 24.10.1
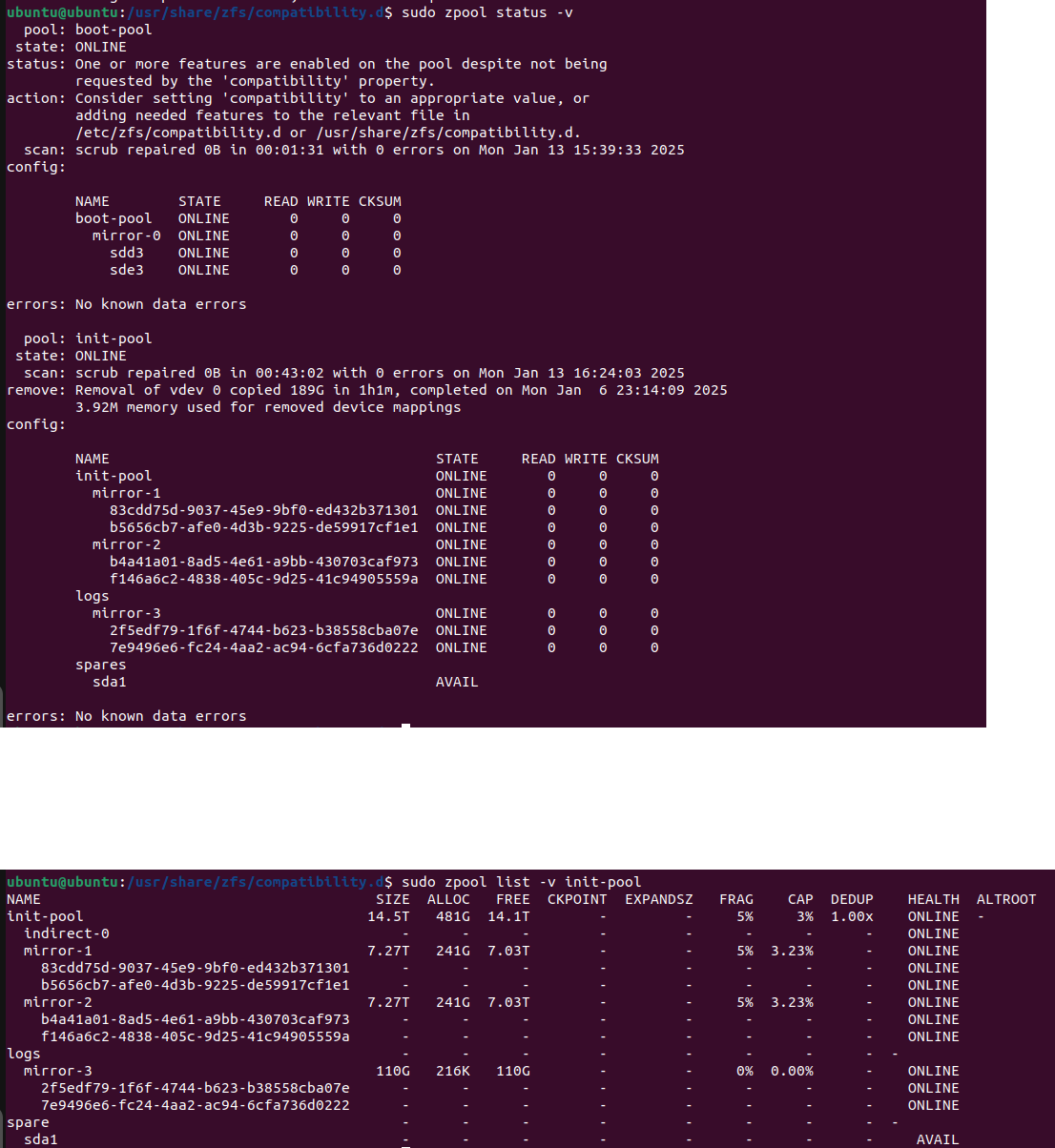
- 1 Pool with 3 mirrored VDEVs
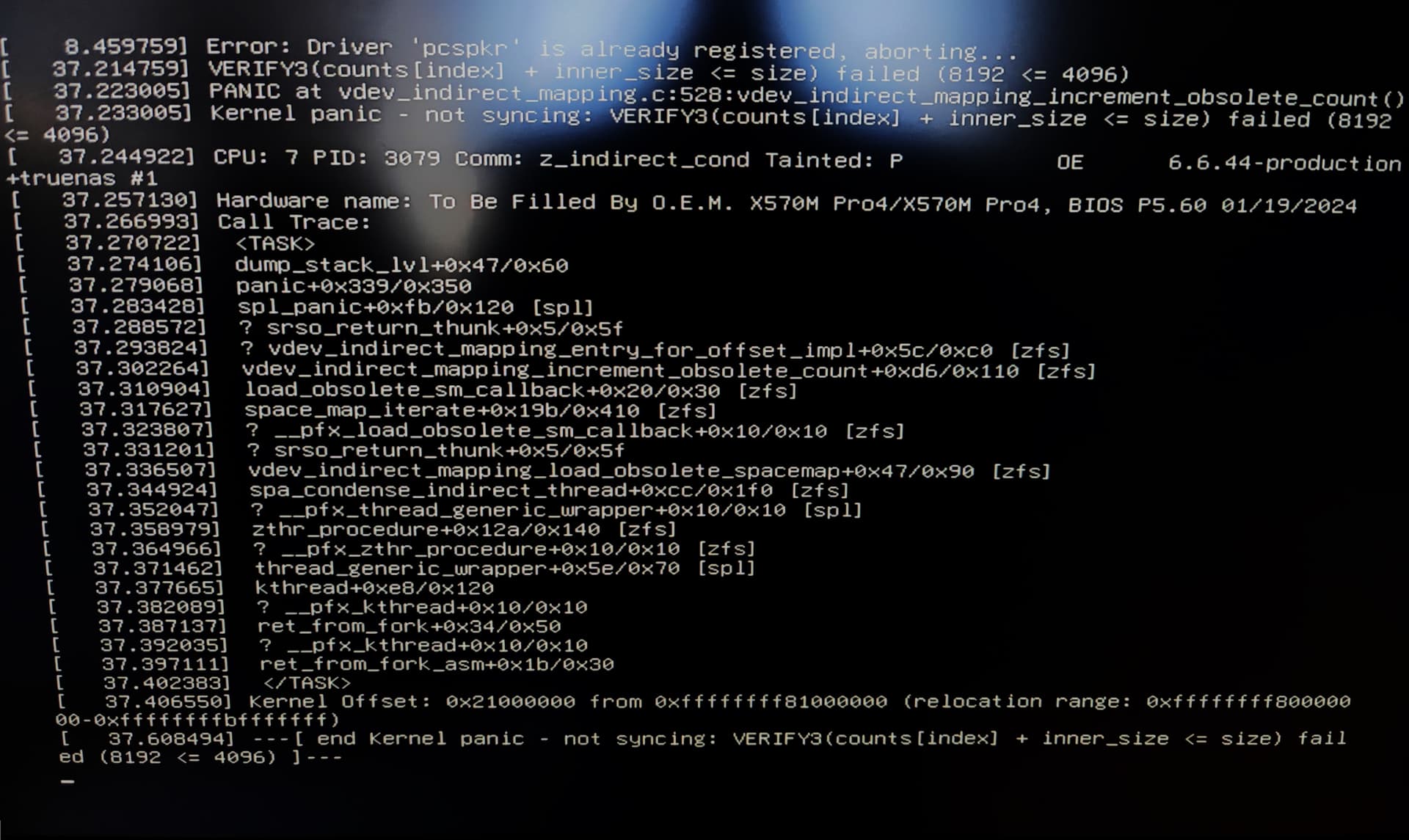
About 7 or 8 days ago, one of my hard drives in one of the mirrored VDEVs went down, all the other drives were reporting back as good, so I decided to offline the drive and remove the VDEV entirely since my overall pool has enough storage space to absorb the data. I reassigned the now extra drive as a spare vdev for the pool. Everything seemed to run fine and I did a SMART test to make sure all the other drives were good, and a scrub to make sure the pool was still healthy - all checks came back with no errors. Then last night I was trying to access my SMB share and I noticed that it was inaccessible, so I tried to log in to the TrueNAS server and realized it was completely frozen. This is the first time this has ever happened, so I rebooted it and when it was starting it went directly into a Kernel Panic. I’ve tried to do research on what may be causing this issue but I haven’t been able to find much aside from one issue that seemed unrelated. So far the only troubleshooting I could think of is running a MEMTEST86 test to make sure the memory is good, but aside from that I don’t know what else to do. Any and all help would be greatly appreciated as this is my production system.