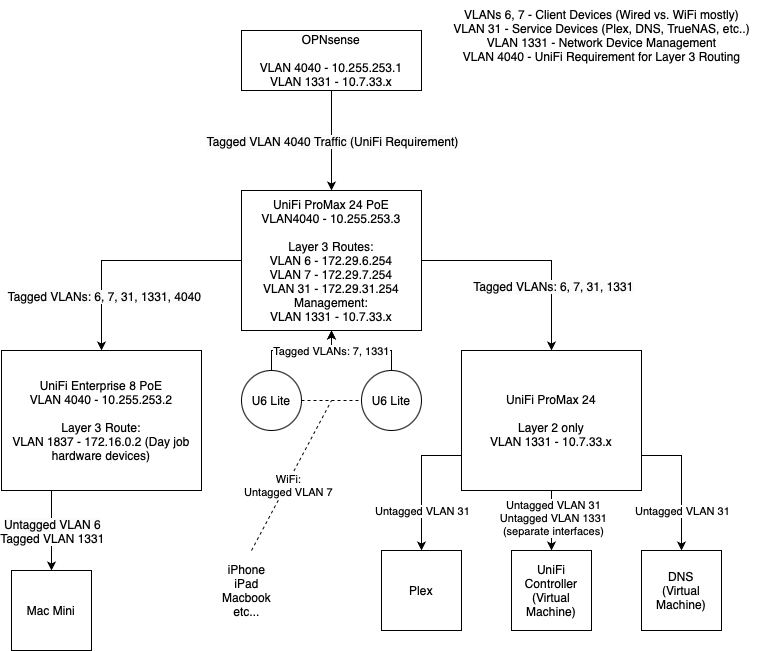
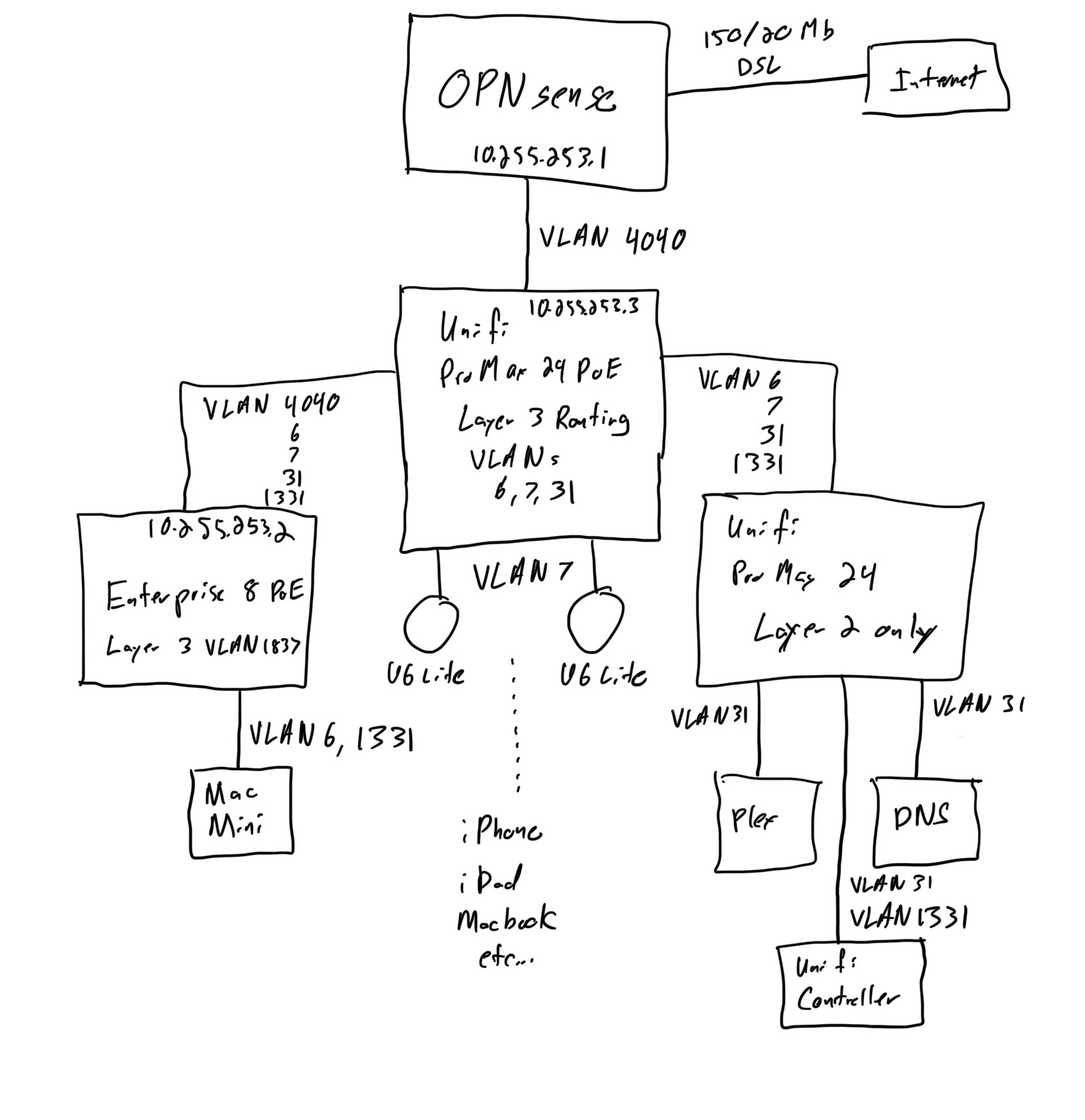
I have a network configuration that ran fine for years using a Cisco SG350 (and before that, an SG300) as the core switch. The core switch is responsible for Layer 3 routing between some of my VLANs (6, 7, 31 in my diagram), my router sits on the other side of it and only sees a single VLAN (4040 now due to UniFi requirements). I originally implemented this because when I tried having the router (at the time pfSense, now OPNsense) manage all of the VLAN routing, I was unable to saturate a 1Gbps link when traffic was transiting between two VLANs.
More recently, I “upgraded” my network to a UniFi Pro Max 24 PoE as the core switch. I already had UniFI access points and some auxiliary UniFi switches (an Enterprise 8 PoE on my desk and a Mini behind my TV), so wanted to consolidate the rest of my network into a single UI for management. Here’s a simplified view of what my network currently looks like (hopefully you can read my handwriting). I am running a self-hosted controller on an XCP-NG VM, but it has behaved quite well in general.
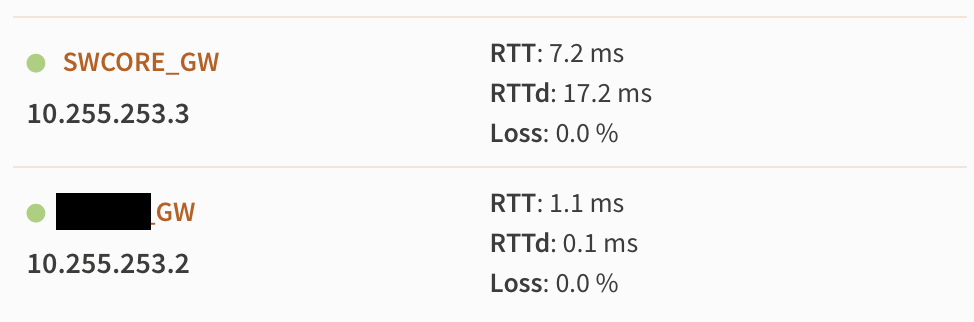
Ever since I installed the Pro Max 24 PoE, I have had sporadic issues with performance of any traffic that needs to transit the Layer 3 routes in my core switch. For management isolation reasons (which are probably overkill, but oh well) I do have some non-routed VLANs that my Mac Mini is on with the switches, but are not accessible unless you are connected directly to a port that supports that VLAN. When I perform a speed test across that VLAN to the Plex server or UniFi controller, it consistently saturates the slowest link (usually 1Gbps) in the path. When I run the same test, across the same physical wires, but via a route that goes through the core switch’s layer 3 routing (so VLAN 6 to VLAN 31), I get absurdly slow speeds, usually <1Mbps. This isn’t completely consistent. I also have issues with websites via the internet, though sometimes those issues appear to apply to one device and not others (most often WiFi but not wired).
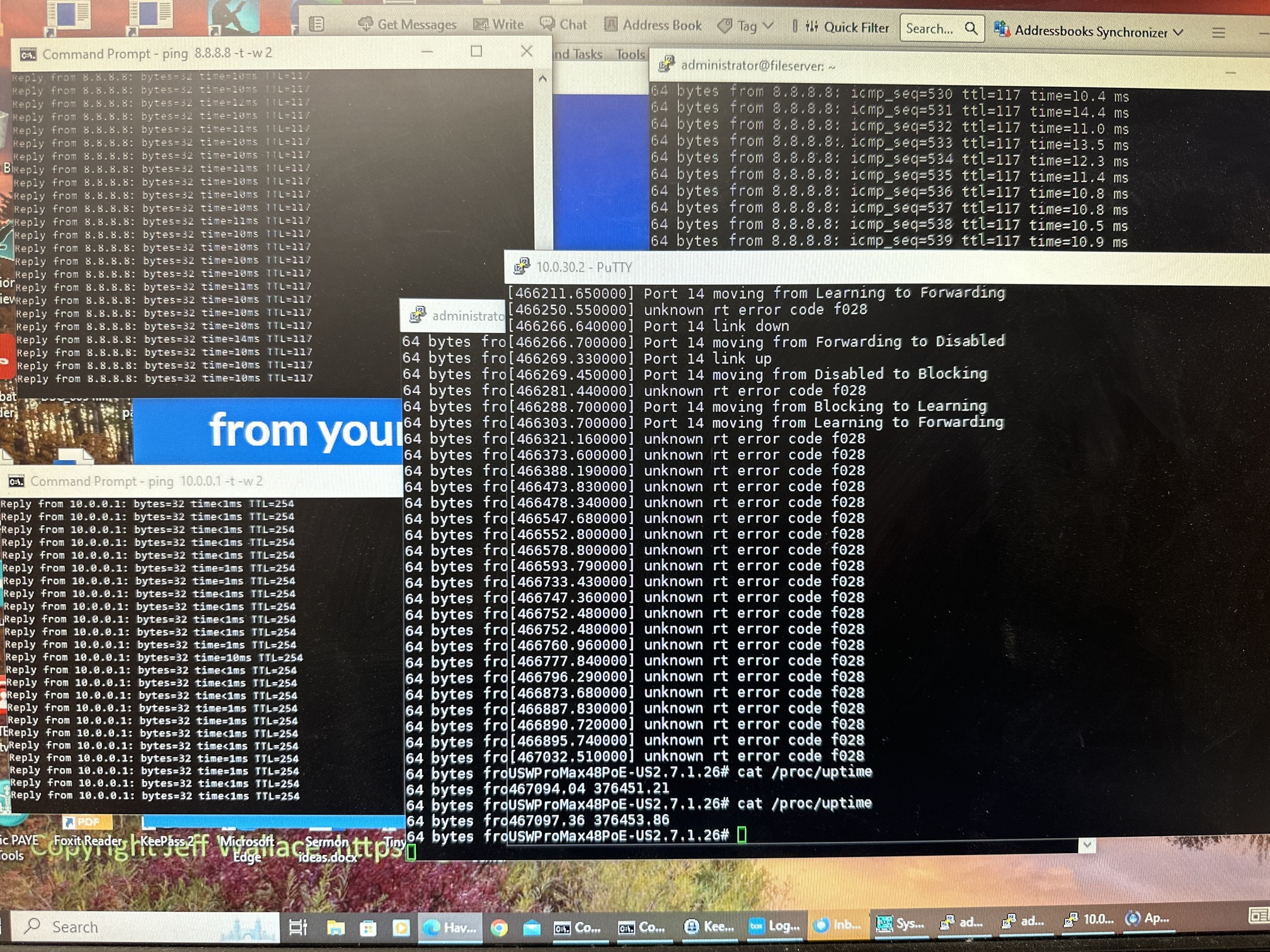
Other troubleshooting I have done includes looking UniFi Controller logs, but those don’t seem to indicate any problems. I’ve also ran Wireshark on a computer while it was being slow with some traffic and see what appears to be a rather high number of TCP Dup Ack, TCP Retransmit and the occasional other TCP error packet.
I don’t think I have a topology that is particularly unusual, and it performed very well when I was using a Cisco switch, making me think it has to be related to the UniFi switch itself. Searching online has mostly turned up complaints about Layer 3 features, not performance, so I can’t tell if this is a common thing or not, but it seems like if it was that Layer 3 would be completely unusable and I do see reports of other more specific issues, so people are using it?
Does anyone have any ideas of what might be happening here? Is this really just my config somehow or is UniFi hardware really that incapable of performing this function? I wouldn’t expect to need a Enterprise switch to do this when Pro Max also advertises as PoE capable…